

【MySQL】MySQL 数据归档神器!pt-archiver 从入门到自动化实战
作为一名常年和 MySQL 打交道的后端开发者,最近深深体会到 “数据膨胀” 的烦恼 —— 业务跑了两年,日志表和历史订单表已经涨到几十 GB,不仅查询越来越慢,连备份都要花大半天。试过手动删数据,结果锁表导致业务卡顿;用存储过程归档,又容易出现事务超时。直到发现 Percona Toolkit 的 pt-archiver,才算找到了解决历史数据治理的最优解!
这篇博客就把我踩过的坑、总结的实操经验分享给大家,从环境搭建到自动化脚本,带你完整掌握 pt-archiver 的用法,让数据库减负更高效~
一、为啥选择 pt-archiver?聊聊我的真实痛点
在遇到 pt-archiver 之前,我试过三种数据清理方案:
- 直接 DELETE:大表删除会锁表,业务直接报超时;
- 存储过程分批删:逻辑繁琐,容易出现事务日志暴涨;
- 复制表 + rename:操作复杂,还可能丢失增量数据。
而 pt-archiver 完美解决了这些问题,它的核心优势的我亲测靠谱:
- 低影响操作:批量处理 + 事务控制,不会长时间占用锁资源,生产环境高峰期也能跑;
- 功能灵活:既能归档到其他数据库,也能导出成文件,还能选择是否保留原数据;
- 轻量易用:Perl 编写的工具,安装简单,命令行参数清晰,上手成本低。
二、环境准备:三步搞定基础配置
工欲善其事,必先利其器。使用 pt-archiver 前,这三步准备工作一定要做扎实,避免后续踩坑~
2.1 先搞懂核心作用,避免用错场景
很多同学容易把 pt-archiver 当成单纯的 “删数据工具”,其实它的核心能力有三个:
- 数据清理:直接删除无用历史数据(比如超过 1 年的日志);
- 数据归档:迁移历史数据到归档库,主库只留近期数据;
- 离线备份:导出数据到 SQL/CSV 文件,方便长期存储。
2.2 创建专用数据库用户
不建议直接用 root 用户操作,给 pt-archiver 创建一个有针对性权限的用户更安全。我在主库(192.168.184.151)和归档库(192.168.184.153)都执行了以下命令:
-- 创建dba用户,允许192.168网段访问
CREATE USER 'dba'@'192.168.%' IDENTIFIED WITH MYSQL_NATIVE_PASSWORD BY 'Id81Gdac_a';
-- 生产环境建议缩小权限范围,这里为了测试方便授予全权限
GRANT ALL ON *.* TO 'dba'@'192.168.%';
⚠️ 注意:归档库最好不要是主库的从库,否则归档操作可能影响主从同步。
2.3 搭建测试环境(附测试数据)
为了让大家能直接上手测试,我整理了完整的测试环境搭建脚本:
主库创建测试表 + 插入数据
USE maria;
-- 创建模拟业务表(含自增主键,实际业务表建议加索引)
CREATE TABLE archiver_test (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) COMMENT '姓名',
age INT COMMENT '年龄',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
);
-- 插入10条测试数据,包含不同年龄和创建时间
INSERT INTO archiver_test (name, age, create_time) VALUES
('张三', 22, '2023-01-15 10:30:00'),
('李四', 28, '2023-03-20 14:20:00'),
('王五', 35, '2023-05-10 09:10:00'),
('赵六', 25, '2023-07-05 16:40:00'),
('孙七', 42, '2023-09-18 11:50:00'),
('周八', 29, '2024-01-22 13:10:00'),
('吴九', 33, '2024-03-15 15:30:00'),
('郑十', 27, '2024-05-28 08:40:00'),
('王十一', 31, '2024-07-12 10:20:00'),
('李十二', 26, '2024-09-03 14:10:00');
归档库创建对应表
-- 创建归档库
CREATE DATABASE archiver_db;
USE archiver_db;
-- 表结构必须和主库一致,包括字段类型、主键和索引
CREATE TABLE archiver_test (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(50) COMMENT '姓名',
age INT COMMENT '年龄',
create_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间'
);
三、核心用法:5 个实战场景直接抄
pt-archiver 的命令格式很统一,核心是--source(源库参数)、--dest(目标库参数)和各种可选参数。下面这 5 个场景是我工作中最常用的,附完整命令和使用心得~
3.1 场景 1:全表归档(保留主库数据)
适合需要备份但不删除主库数据的场景,比如年度数据备份:
pt-archiver \
--source h=192.168.184.151,u=dba,p='Id81Gdac_a',D=maria,t=archiver_test \
--dest h=192.168.184.153,u=dba,p='Id81Gdac_a',D=archiver_db,t=archiver_test \
--where '1=1' \ # 1=1表示全表,实际可加条件
--progress 5 \ # 每处理5行输出一次进度(测试用,生产建议10000)
--limit=5 \ # 每次处理5行
--txn-size=5 \ # 每5行提交一次事务
--no-safe-auto-increment \ # 避免归档表自增主键冲突
--statistics \ # 输出统计信息
--no-delete # 关键:不删除主库数据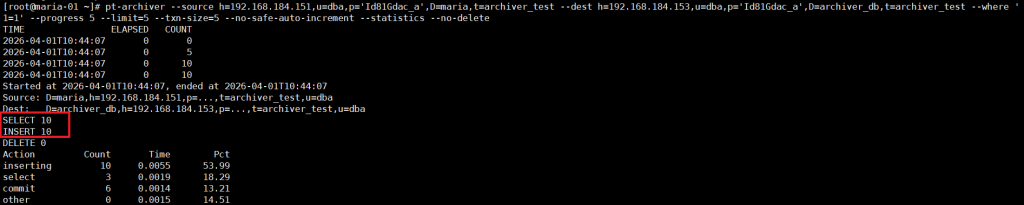
✅ 执行后主库数据不变,归档库会同步所有数据,适合备份场景。
3.2 场景 2:全表归档 + 删除主库数据
适合主库不需要保留历史数据的场景,比如日志表清理:
pt-archiver \
--source h=192.168.184.151,u=dba,p='Id81Gdac_a',D=maria,t=archiver_test \
--dest h=192.168.184.153,u=dba,p='Id81Gdac_a',D=archiver_db,t=archiver_test \
--where '1=1' \
--progress 10000 \
--limit=10000 \
--txn-size=10000 \
--no-safe-auto-increment \
--statistics \
--purge # 关键:归档后删除主库数据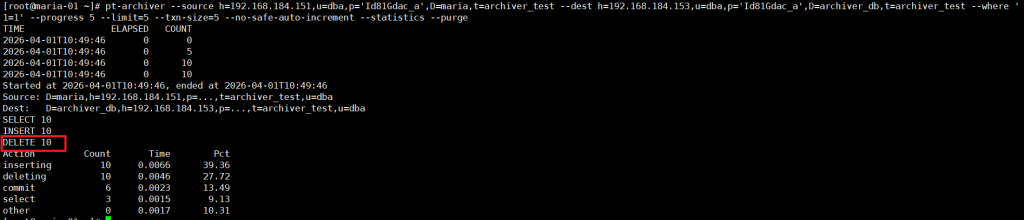
⚠️ 注意:生产环境一定要先测试条件是否正确,避免误删数据!
3.3 场景 3:只删除数据(不归档)
适合完全无用的数据清理,比如测试数据:
pt-archiver \
--source h=192.168.184.151,u=dba,p='Id81Gdac_a',D=maria,t=archiver_test \
--where 'age>40' \ # 只删除年龄大于40的数据
--progress 10000 \
--limit=10000 \
--txn-size=10000 \
--statistics \
--purge # 无需--dest参数,直接删除
✅ 这个命令我常用于清理过期测试数据,比直接 DELETE 高效且安全。
3.4 场景 4:按条件归档(最常用)
实际业务中用得最多的场景,比如归档 2023 年之前的历史数据:
# 先清空归档表(避免重复归档,可选)
mysql -h192.168.184.153 -udba -p'Id81Gdac_a' -e "TRUNCATE TABLE archiver_db.archiver_test;"
# 归档2023年及之前的数据,并删除主库对应数据
pt-archiver \
--source h=192.168.184.151,u=dba,p='Id81Gdac_a',D=maria,t=archiver_test \
--dest h=192.168.184.153,u=dba,p='Id81Gdac_a',D=archiver_db,t=archiver_test \
--where 'create_time < "2024-01-01 00:00:00"' \ # 按时间条件筛选
--progress 10000 \
--limit=10000 \
--txn-size=10000 \
--no-safe-auto-increment \
--statistics \
--purge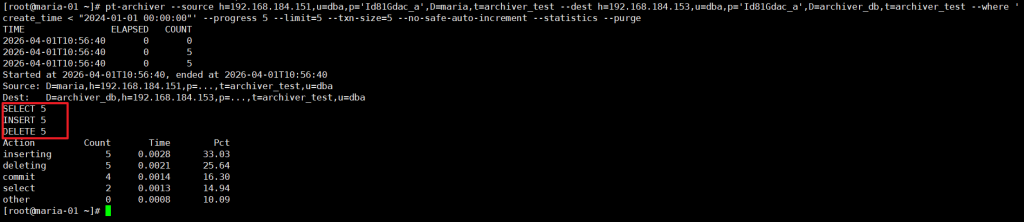
💡 心得:条件字段(如 create_time)一定要加索引,否则会全表扫描,影响主库性能!
3.5 场景 5:归档到文件(离线存储)
适合需要长期离线存储的场景,比如归档到 CSV 文件后备份到云存储:
# 归档为CSV文件(便于Excel分析)
pt-archiver \
--source h=192.168.184.151,u=dba,p='Id81Gdac_a',D=maria,t=archiver_test \
--where 'create_time < "2024-01-01 00:00:00"' \
--progress 10000 \
--limit=10000 \
--txn-size=10000 \
--statistics \
--purge \
--file=./2023_archiver.csv \ # 输出文件路径
--output-format=csv # 指定格式为CSV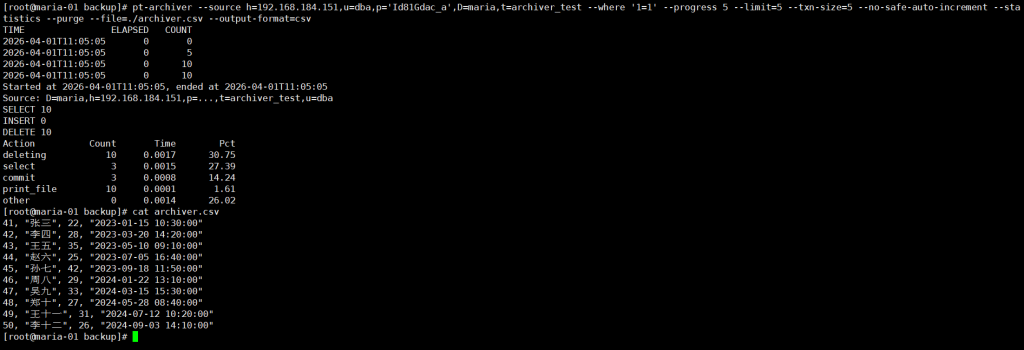
✅ 执行后会在当前目录生成 CSV 文件,里面包含所有归档数据,方便后续导入其他系统或备份。
四、自动化归档:Shell 脚本 + crontab 实现无人值守
手动执行命令适合临时操作,长期维护还是需要自动化。下面分享我正在用的日志表自动化归档脚本,每天凌晨自动运行,省心又靠谱~
4.1 自动化脚本(archiver_log.sh)
#!/bin/bash
# 日志表自动化归档脚本 - 云扬のBlog专属版
# 功能:每天归档主库中超过30天的日志数据到归档库
# -------------------------- 配置参数 --------------------------
# 源库信息
source_host="192.168.184.151"
source_db="maria"
source_table="log_table"
source_user="dba"
source_password="Id81Gdac_a"
# 归档库信息
dest_host="192.168.184.153"
dest_db="archiver_db"
dest_table="log_table"
dest_user="dba"
dest_password="Id81Gdac_a"
# 归档条件:超过30天的数据
where_clause="log_time > DATE_SUB(NOW(), INTERVAL 30 DAY)"
# 日志输出路径(方便排查问题)
log_file="/var/log/pt_archiver/$(date +%Y%m%d)_archiver.log"
# -------------------------- 初始化操作 --------------------------
# 创建日志目录(如果不存在)
if [ ! -d "/var/log/pt_archiver" ]; then
mkdir -p /var/log/pt_archiver
chmod 755 /var/log/pt_archiver
fi
# -------------------------- 执行归档 --------------------------
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 开始执行30天前日志归档..." >> $log_file
pt-archiver
--source h=$source_host,D=$source_db,t=$source_table,u=$source_user,p=$source_password
--dest h=$dest_host,D=$dest_db,t=$dest_table,u=$dest_user,p=$dest_password
--where "$where_clause"
--progress=10000
--bulk-delete
--limit=1000
--commit-each
--statistics >> $log_file
# -------------------------- 结果检查 --------------------------
if [ $? -eq 0 ]; then
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 归档执行成功!" >> $log_file
else
echo "[$(date +'%Y-%m-%d %H:%M:%S')] 归档执行失败!" >> $log_file
# 这里可以加邮件告警,比如用mail命令发送失败通知
exit 1
fi
4.2 脚本部署与定时配置
- 保存脚本到指定目录:
mkdir -p /data/script
vi /data/script/archiver_log.sh
# 粘贴上面的脚本内容,保存退出
- 赋予执行权限:
chmod +x /data/script/archiver_log.sh
- 测试脚本是否能正常运行:
sh /data/script/archiver_log.sh
测试后可以检查日志文件和归档库数据,确认没有问题再配置定时任务。
- 配置 crontab 定时执行:
# 编辑crontab任务
crontab -e
# 添加以下内容(每天凌晨2点执行)
0 2 * * * /data/script/archiver_log.sh
✅ 这样每天凌晨 2 点(业务低峰期)脚本会自动运行,无需人工干预。
五、我的避坑指南:这些经验一定要记牢
在使用 pt-archiver 的过程中,我踩过不少坑,总结了以下 5 点关键经验,能帮你少走很多弯路:
- 先备份再操作:无论什么场景,执行归档 / 删除前一定要备份关键数据,我曾经因为条件写错差点误删重要数据,幸好有备份及时恢复;
- 测试环境先验证:新脚本或命令一定要先在测试环境跑通,确认参数正确、不会影响业务后,再放到生产环境;
- 控制批量大小:
--limit和--txn-size不要设置太大,建议 1000-10000 行,否则可能导致事务过长,影响主库性能; - 索引必不可少:
--where条件中的字段一定要加索引,否则会触发全表扫描,我曾经没加索引导致主库 CPU 飙升到 90%; - 权限最小化:生产环境中,dba 用户的权限不要给太宽,只授予源库和归档库的必要权限即可,降低安全风险。
总结
pt-archiver 真的是 MySQL 数据归档的 “瑞士军刀”,功能强大又易用。通过本文的环境搭建、核心用法和自动化脚本,相信你也能快速掌握它的使用技巧。
自从用了 pt-archiver,我们的主库表体积减少了 60%,查询速度提升了 3 倍,备份时间从 2 小时缩短到 20 分钟,效果非常明显。如果你也在被历史数据膨胀的问题困扰,不妨试试这个工具,相信会给你带来惊喜~
如果在使用过程中遇到问题,欢迎在评论区交流,我会及时回复大家!

