

【MySQL】MySQL分区实战指南:从原理到落地的完整攻略
前言:为什么大表必须学会分区?
作为一名长期深耕后端开发的工程师,相信很多同学都遇到过这样的痛点:随着业务增长,单表数据量突破千万甚至亿级后,即使加了索引,查询依然卡顿;定期清理历史数据时,delete 语句执行几小时还会导致从库延迟。其实这些问题,用 MySQL 分区就能完美解决。今天就从原理到实操,带大家彻底掌握分区技术,让大表查询效率翻倍!
一、MySQL 分区:大表优化的 “手术刀”
1.1 分区的核心优势
- 查询提速:只扫描目标分区,避免全表扫描。比如按月分区的订单表,查询近 3 个月数据时,仅需访问 3 个分区,效率提升显著。
- 维护高效:删除历史数据无需 delete,直接 drop 分区,秒级完成且不影响业务。
- 存储扩展:不同分区可部署在不同磁盘,冷热数据分离,降低存储成本的同时保证热数据性能。
1.2 哪些场景适合用分区?
- 数据量超 1000 万的大表(如订单表、日志表);
- 需按时间范围查询数据(如报表统计、历史记录查询);
- 有定期归档 / 删除历史数据需求(如日志保留 6 个月);
- 冷热数据访问频率差异大(如近 3 个月数据高频访问,一年前数据极少查询)。
1.3 避坑指南:分区前必须知道的限制
- MySQL 分区有限制:不支持外键和全文索引,临时表不能分区,NULL 值会归入范围分区的最小分区;
- 分区键选不对,一切都白费:优先选查询频繁的过滤字段(如 create_time),还要保证数据均匀分布,避免热点分区;
- 分区数量不是越多越好:建议单分区数据量控制在 100 万 – 1000 万,过多分区会增加元数据开销,反而拖慢性能。
二、5 种核心分区类型 + 实操案例
MySQL支持多种分区类型,不同类型适用于不同场景。以下为5种核心分区类型的定义、适用场景及完整创建案例。
| 分区类型 | 解释 | 适用场景举例 |
| 范围分区 | 根据某个字段的范围条件将数据分区 | 订单表按订单日期进行范围分区 日志表按照日志记录的时间进行范围分区 |
| 列表分区 | 基于枚举出的值进行分区 | 商品表按照商品类别进行列表分区 用户信息根据地区进行列表分区 |
| 哈希分区 | 根据某个列的哈希值进行分区 | 用户信息按照用户id进行哈希分区 订单表按照订单ID进行哈希分区 |
| 按键分区 | 根据某个列的键值将表数据分割成不同的分区 | 用户信息表按照用户ID进行按键分区 日志表按照日志ID进行按键分区 |
| 子分区 | 对分区表中的每个分区再进一步划分 | 日志表对年份进行分区之后,再对日期做哈希分区 |
2.1 范围分区:最常用的时间分区方案
- 定义:按“连续的数值范围”拆分数据,如按分数段(0-60、60-80)、日期范围(2023年、2024年)。
- 适用场景:数据有明确范围划分,且查询多基于范围过滤(如按时间查询历史数据)。
案例1:按整数范围分区(学生成绩表)
按分数将学生成绩分为“不及格(<60)”“良好(60-80)”“优秀(80-100)”三个分区:
CREATE TABLE range_student_scores (
id INT AUTO_INCREMENT,
student_name VARCHAR(10) NOT NULL COMMENT '学生姓名',
score INT NOT NULL COMMENT '考试分数',
PRIMARY KEY (id,score)
)
-- 按score字段范围分区
PARTITION BY RANGE (score) (
PARTITION p_fail VALUES LESS THAN (60) COMMENT '不及格(0-59)',
PARTITION p_good VALUES LESS THAN (80) COMMENT '良好(60-79)',
PARTITION p_excellent VALUES LESS THAN (101) COMMENT '优秀(80-100)'
);查看下数据文件:
cd /data/mysql/data/partition_db/ && ll | grep range_student_scores
案例2:按时间范围分区(系统日志表)
按年份分区,存储不同年份的日志数据:
CREATE TABLE range_system_log (
id INT NOT NULL,
log_content TEXT NOT NULL COMMENT '日志内容',
log_date DATE NOT NULL COMMENT '日志日期'
)
-- 按log_date的年份分区(通过YEAR()函数提取年份)
PARTITION BY RANGE (YEAR(log_date)) (
PARTITION p2022 VALUES LESS THAN (2023) COMMENT '2022年日志',
PARTITION p2023 VALUES LESS THAN (2024) COMMENT '2023年日志',
PARTITION p2024 VALUES LESS THAN (2025) COMMENT '2024年日志'
);2.2 列表分区:离散数据的精准拆分
- 定义:按“离散的数值列表”拆分数据,如按日志类型(1=info、2=warn、3=error)、地区ID(10=北京、20=上海)。
- 注意:仅支持整数类型,非整数需通过函数转化(如
MONTH(log_date)将日期转为月份整数)。
案例1:按整型列表分区(日志类型表)
按日志类型(1=信息、2=警告、3=错误)分区:
CREATE TABLE list_log_type (
id INT NOT NULL,
log_msg VARCHAR(50) NOT NULL COMMENT '日志信息',
log_type INT NOT NULL COMMENT '日志类型:1=info,2=warn,3=error'
)
-- 按log_type的离散值分区
PARTITION BY LIST (log_type) (
PARTITION p_info VALUES IN (1) COMMENT '信息日志',
PARTITION p_warn VALUES IN (2) COMMENT '警告日志',
PARTITION p_error VALUES IN (3) COMMENT '错误日志'
);案例2:按时间列表分区(季度日志表)
按月份拆分季度(1-3月=Q1、4-6月=Q2等):
CREATE TABLE list_quarter_log (
id INT AUTO_INCREMENT,
log_content TEXT NOT NULL COMMENT '日志内容',
log_date DATE NOT NULL COMMENT '日志日期',
PRIMARY KEY (id,log_date)
)
-- 按MONTH(log_date)转化后的月份整数分区
PARTITION BY LIST (MONTH(log_date)) (
PARTITION p_q1 VALUES IN (1,2,3) COMMENT '第一季度(1-3月)',
PARTITION p_q2 VALUES IN (4,5,6) COMMENT '第二季度(4-6月)',
PARTITION p_q3 VALUES IN (7,8,9) COMMENT '第三季度(7-9月)',
PARTITION p_q4 VALUES IN (10,11,12) COMMENT '第四季度(10-12月)'
);2.3 哈希分区:数据均匀分散的利器
定义:通过哈希函数将数据“均匀分配”到指定数量的分区,避免手动定义范围或列表。
适用场景:数据无明显范围/列表特征,需均匀分散数据以避免热点分区(如用户表按用户ID分区)。
案例1:按整数哈希分区(学生信息表)
按student_id哈希,均匀分配到4个分区:
CREATE TABLE hash_student_info (
id INT AUTO_INCREMENT,
student_id INT NOT NULL COMMENT '学生ID',
student_name VARCHAR(50) NOT NULL COMMENT '学生姓名',
PRIMARY KEY (id,student_id)
)
-- 按student_id哈希,分为4个分区
PARTITION BY HASH(student_id)
PARTITIONS 4;案例2:按时间哈希分区(员工生日表)
按生日年份哈希,分配到4个分区:
CREATE TABLE hash_employee_birth (
id INT AUTO_INCREMENT,
emp_name VARCHAR(50) NOT NULL COMMENT '员工姓名',
birth_date DATE NOT NULL COMMENT '生日日期',
PRIMARY KEY (id,birth_date)
)
-- 按YEAR(birth_date)提取年份后哈希,分为4个分区
PARTITION BY HASH(YEAR(birth_date))
PARTITIONS 4;2.4 按键分区:字符串分区的最优解
定义:类似哈希分区,但由MySQL自动选择哈希函数(优化字符串等类型的哈希效果),支持非整数分区字段。
特点:若不指定分区键,默认使用主键;无主键则使用非空唯一索引。
案例1:默认主键按键分区(用户表)
不指定分区键,默认按主键id分区:
CREATE TABLE key_user_info (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '用户ID(默认分区键)',
username VARCHAR(20) NOT NULL COMMENT '用户名'
)
-- 按默认主键分区,分为4个分区
PARTITION BY KEY()
PARTITIONS 4;案例2:按字符串字段按键分区(学生姓名表)
按字符串name作为分区键,MySQL自动优化哈希:
CREATE TABLE key_student_name (
id INT AUTO_INCREMENT,
name VARCHAR(20) NOT NULL COMMENT '学生姓名(分区键)',
PRIMARY KEY (id,name)
)
-- 按name字段按键分区,分为4个分区
PARTITION BY KEY(name)
PARTITIONS 4;2.5 子分区:复杂场景的组合策略
定义:在“主分区”基础上进一步拆分“子分区”,支持组合分区策略(如先按时间范围分区,再按哈希子分区)。
适用场景:需同时满足两种分区需求,如“按年份范围分区(主分区)+ 按日期哈希分散数据(子分区)”。
案例:范围-哈希子分区(用户生日表)
先按生日年份范围分主分区,再按日期哈希分子分区:
CREATE TABLE sub_employee_birth (
id INT AUTO_INCREMENT,
emp_name VARCHAR(50) NOT NULL,
birth_date DATE NOT NULL,
PRIMARY KEY (id,birth_date)
)
-- 主分区:按生日年份范围分区
PARTITION BY RANGE (YEAR(birth_date))
-- 子分区:按生日日期哈希,每个主分区下分2个子分区
SUBPARTITION BY HASH(TO_DAYS(birth_date))
SUBPARTITIONS 2 (
PARTITION p2000 VALUES LESS THAN (2010) COMMENT '主分区:2010年前生日',
PARTITION p2010 VALUES LESS THAN (2020) COMMENT '主分区:2010-2019年生日',
PARTITION p2020 VALUES LESS THAN (2030) COMMENT '主分区:2020年后生日'
);案例:列表-按键子分区(员工部门表)
CREATE TABLE sub_employees (
id INT,
employee_name VARCHAR(50),
department_id INT
)
PARTITION BY list (department_id)
SUBPARTITION BY KEY (id)
SUBPARTITIONS 4 (
PARTITION p1 VALUES IN (1, 2) (
SUBPARTITION s1,
SUBPARTITION s2,
SUBPARTITION s3,
SUBPARTITION s4
),
PARTITION p2 VALUES IN (3, 4) (
SUBPARTITION s5,
SUBPARTITION s6,
SUBPARTITION s7,
SUBPARTITION s8
)
);三、分区表的日常管理技巧
创建分区表后,需定期进行维护操作(如新增分区、删除历史分区、查看分区数据)。以下为常用管理操作的实操案例。
3.1 范围分区管理(最常用)
1. 新增分区(如新增2025年日志分区)
针对range_system_log表(按年份分区),新增2025年分区:
-- 新增2025年分区(VALUES LESS THAN (2026)表示2025年及之前数据)
ALTER TABLE range_system_log
ADD PARTITION (PARTITION p2025 VALUES LESS THAN (2026));
-- 验证分区是否创建成功
SHOW CREATE TABLE range_system_log;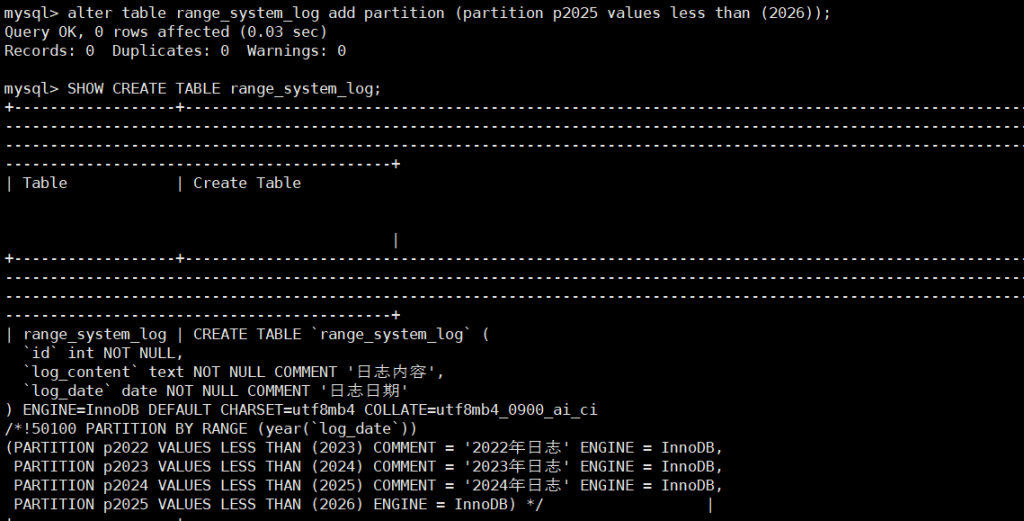
2. 查看分区数据(如查看2024年日志)
写入测试数据
INSERT INTO range_system_log (id, log_content, log_date) VALUES
(1, 'Test message 2020', '2020-01-01'),
(2, 'Test message 2020', '2020-02-01'),
(3, 'Test message 2020', '2020-03-01'),
(4, 'Test message 2021', '2021-01-01'),
(5, 'Test message 2021', '2021-02-01'),
(6, 'Test message 2021', '2021-03-01'),
(7, 'Test message 2022', '2022-01-01'),
(8, 'Test message 2022', '2022-02-01'),
(9, 'Test message 2022', '2022-03-01'),
(10, 'Test message 2023', '2023-01-01'),
(11, 'Test message 2023', '2023-02-01'),
(12, 'Test message 2023', '2023-03-01');
查看分区的数据
-- 查看指定分区(p2023)的数据
SELECT * FROM range_system_log PARTITION (p2023);
-- 统计所有分区的数据量(实用!)
SELECT
PARTITION_NAME AS '分区名',
TABLE_ROWS AS '数据量'
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME = 'range_system_log';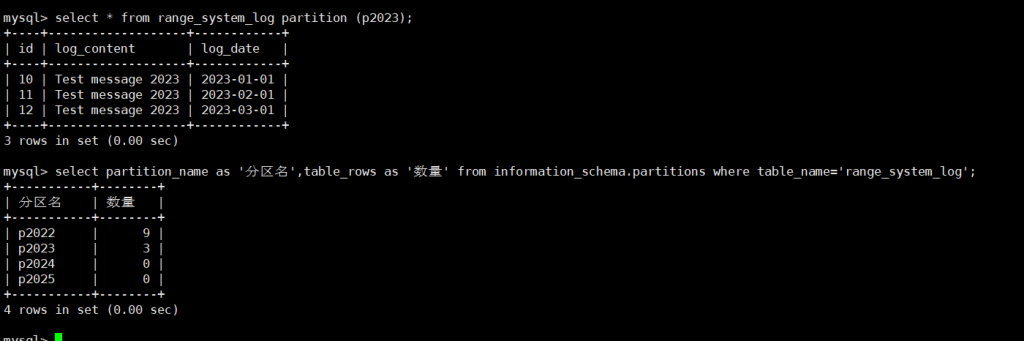
3. 删除分区(如删除2022年历史日志)
注意:删除分区会同时删除分区内的所有数据,且不可恢复!
-- 删除2022年分区(p2022)
ALTER TABLE range_system_log
DROP PARTITION p2022;
-- 验证分区是否删除
SHOW CREATE TABLE range_system_log;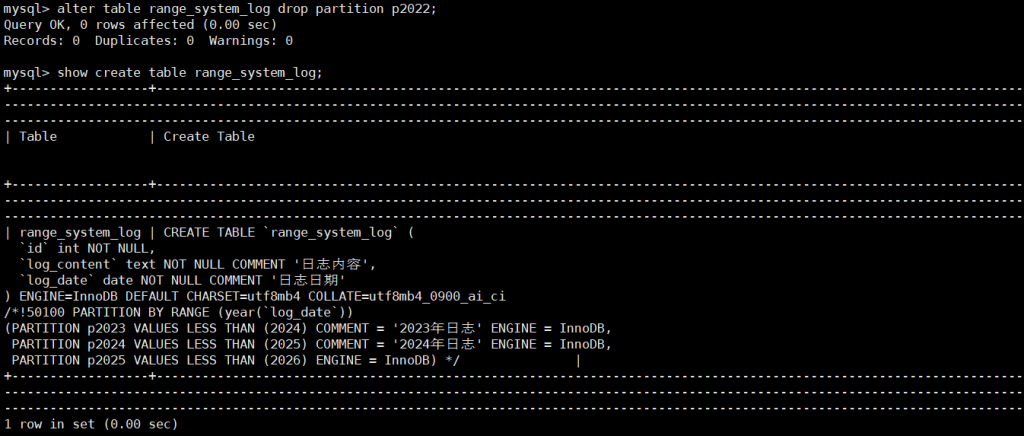
4. 分区交换(将分区数据与临时表交换)
适用于数据迁移场景(如将2023年日志迁移到临时表归档):
-- 1. 创建与原表结构一致的临时表(不含分区)
CREATE TABLE range_log_tmp LIKE range_system_log;
ALTER TABLE range_log_tmp REMOVE PARTITIONING; -- 删除临时表的分区配置
-- 2. 交换p2023分区与临时表数据(临时表数据需符合p2023分区范围)
ALTER TABLE range_system_log
EXCHANGE PARTITION p2023 WITH TABLE range_log_tmp;
-- 3. 验证交换结果(原表p2023数据为空,临时表包含原p2023数据)
SELECT * FROM range_system_log PARTITION (p2023);
SELECT * FROM range_log_tmp;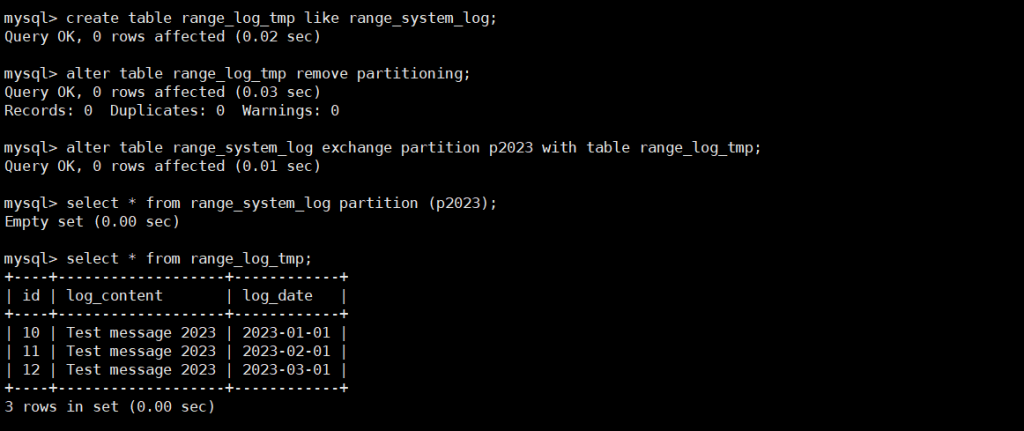
5.重建分区
ALTER TABLE range_system_log REBUILD PARTITION p2023, p2024, p2025;3.2 列表分区管理
1. 新增分区(如新增“调试日志”类型)
针对list_log_type表(按日志类型分区),新增0=调试日志分区:
ALTER TABLE list_log_type
ADD PARTITION (PARTITION p_debug VALUES IN (0) COMMENT '调试日志');
-- 验证分区是否创建成功
SHOW CREATE TABLE list_log_type;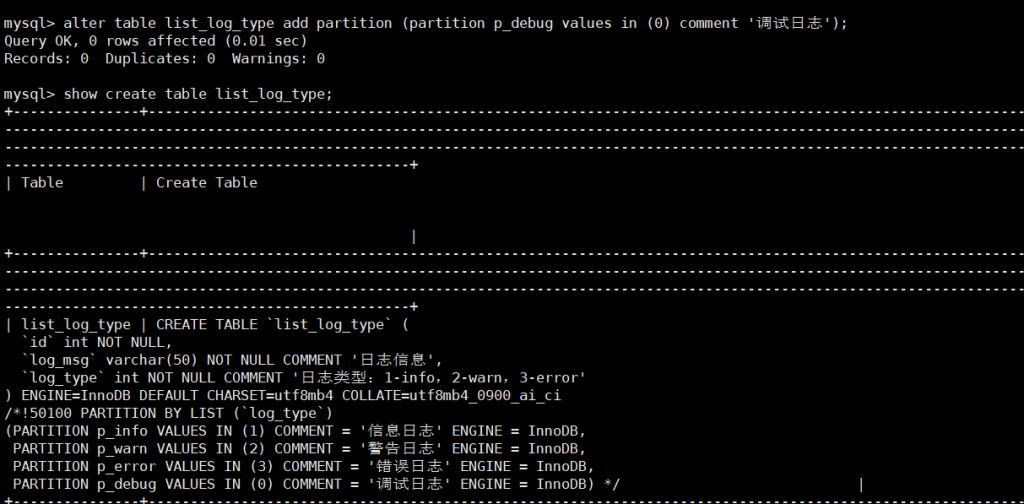
2.查询分区 (如查询“错误日志”分区)
写入测试数据
INSERT INTO list_log_type (id, log_msg, log_type) VALUES
(1, 'Information message 1', 1),
(2, 'Information message 2', 1),
(3, 'Information message 3', 1),
(4, 'Warning message 1', 2),
(5, 'Warning message 2', 2),
(6, 'Warning message 3', 2),
(7, 'Error message 1',3),
(8, 'Error message 2', 3),
(9, 'Error message 3', 3);查询分区数据
select * from list_log_type partition (p_error);2. 删除分区(如删除“调试日志”分区)
ALTER TABLE list_log_type
DROP PARTITION p_debug;
-- 验证分区是否删除
SHOW CREATE TABLE list_log_type;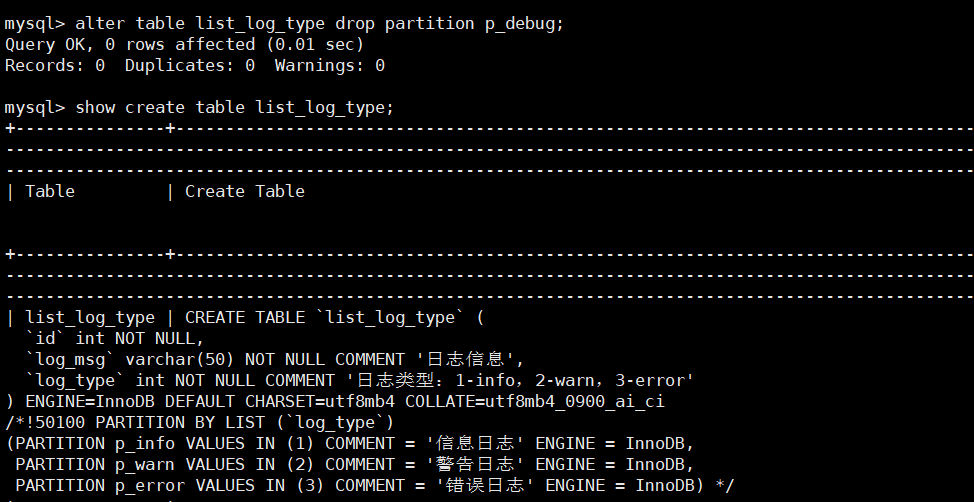
3.3 哈希/按键分区管理(增减分区数量)
哈希与按键分区不支持直接新增/删除单个分区,需通过COALESCE(减少分区)或ADD PARTITION(增加分区)调整总数:
-- 针对hash_student_info表(原4个分区)
-- 1. 减少1个分区(总数变为3)
ALTER TABLE hash_student_info COALESCE PARTITION 1;
-- 2. 增加2个分区(总数变为5)
ALTER TABLE hash_student_info ADD PARTITION PARTITIONS 2;
-- 针对key_user_info表(原4个分区)
-- 1. 减少1个分区(总数变为3)
ALTER TABLE key_user_info COALESCE PARTITION 1;
-- 2. 增加2个分区(总数变为5)
ALTER TABLE key_user_info ADD PARTITION PARTITIONS 2;3.4 子分区管理
1. 删除子分区(如删除p2000主分区下的子分区)
-- 删除p2000主分区(子分区会随主分区一起删除)
ALTER TABLE sub_employee_birth
DROP PARTITION p2000;2. 调整子分区范围(如扩展p2020主分区范围)
-- 将p2020主分区范围从“<2030”调整为“<MAXVALUE”
ALTER TABLE sub_employee_birth
REORGANIZE PARTITION p2020 INTO (
PARTITION p2020 VALUES LESS THAN MAXVALUE
);注意:在使用REORGANIZE PARTITION重组范围分区时,除了最后一个分区可以扩展范围外,不能改变所有分区的总范围。
四、分区 vs 分库分表:该怎么选?
很多同学会混淆这两个概念,其实核心区别在于数据存储范围和复杂度,一张表讲清楚:
| 维度 | MySQL分区 | 分库分表(如ShardingSphere) |
| 数据存储范围 | 单库内,分区文件仍在同一数据库实例 | 跨库跨实例,数据分散在多个库/表 |
| 逻辑形态 | 逻辑上是单表,用户无需感知分区 | 逻辑上是多表,需通过中间件路由 |
| 适用数据量 | 单表1000万-10亿(单库性能上限内) | 单表10亿以上(突破单库性能瓶颈) |
| 复杂度 | 低(MySQL原生支持,无需额外组件) | 高(需中间件、分布式事务等) |
选择建议:
- 单库内数据量未突破10亿,优先用MySQL分区(低成本、易维护);
- 数据量超10亿或需跨实例扩展,再考虑分库分表(如电商订单表、用户表)。
五、生产环境最佳实践
- 分区键选择:优先选择查询频率最高的字段(如订单表的 create_time),确保查询能命中分区;
- 分区数量:建议单个表分区数不超过 50 个,过多会增加元数据开销;
- 预留分区:创建表时提前预留未来 1-2 年的分区,避免后续频繁扩容;
- 定期维护:每月检查分区数据分布,对数据倾斜的分区及时调整;
- 备份策略:对重要分区单独备份,降低恢复风险。
结语
MySQL 分区是大表优化的核心技术之一,合理使用能大幅提升查询效率和维护便利性。但分区不是银弹,需结合业务场景选择合适的分区类型和策略。如果你的业务中也有大表性能瓶颈,不妨试试文中的方案,欢迎在评论区分享你的实践经验!

