

【MySQL】MySQL 分库分表实战:MyCAT 从配置到落地全攻略
大家好,我是云扬!之前分享过 MyCAT 的安装与基础配置,今天就带大家深入实战 —— 用 MyCAT 实现分库分表,包括用户管理、数据源配置、全局表 / 分片表 / ER 表的实操,全程附完整命令和避坑技巧,新手也能跟着做~
一、MyCAT 核心管理命令(必记!)
在开始分库分表前,先掌握这些高频管理命令,后续配置会事半功倍。所有命令均在 MyCAT 服务器(192.168.184.153)上执行,直接在 MySQL 客户端输入即可。
1. 用户管理:创建 / 查看 / 删除
MyCAT 的用户独立于 MySQL,需单独配置,适合权限隔离:
-- 创建用户(支持IP限制、事务类型配置)
/*+ mycat:createUser{
"username":"test_user",
"password":"IjdagaT13",
"ip":"127.0.0.1", -- 仅允许本地访问
"transactionType":"xa" -- 分布式事务类型
} */;
-- 查看所有用户
/*+ mycat:showUsers */;
-- 删除用户
/*+ mycat:dropUser{"username":"test_user"} */;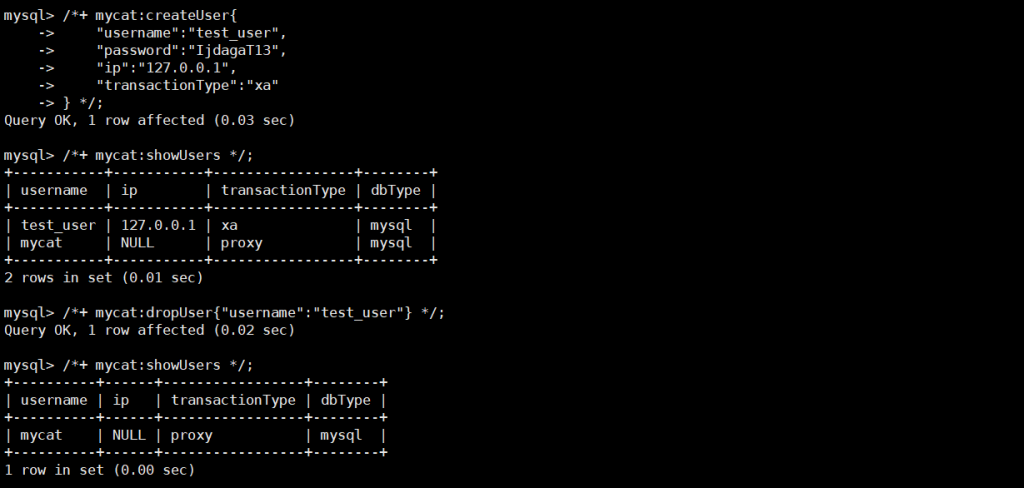
用户配置文件会自动生成在 /usr/local/mycat/conf/users/ 目录下,文件名格式为「用户名.user.json」,可直接修改文件调整配置(需重启 MyCAT 生效)。

2. 数据源管理:对接真实 MySQL 节点
数据源是 MyCAT 与底层 MySQL 数据库的连接配置,每个数据源对应一个 MySQL 实例(主从均可):
-- 创建数据源(主库/从库均可)
/*+ mycat:createDataSource{
"name":"test01", -- 数据源名称(唯一)
"url":"jdbc:mysql://192.168.184.151:3306/?useSSL=false&characterEncoding=UTF-8",
"user":"mycat_rw", -- MySQL中授权的账号(需有增删改查权限)
"password":"Ud9_a8Gca1"
} */;
-- 查看所有数据源状态(重点看status是否为OK)
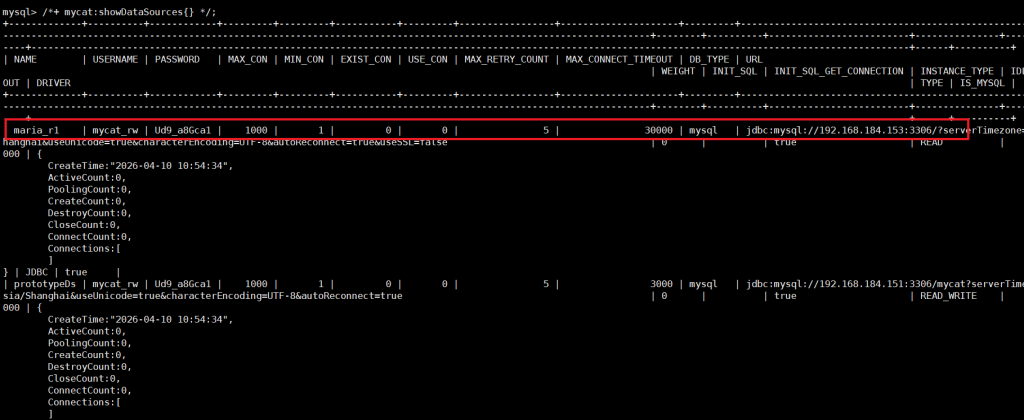
/*+ mycat:showDataSources{} */;
-- 删除数据源(需先移除关联的集群)
/*+ mycat:dropDataSource{"name":"test01"} */;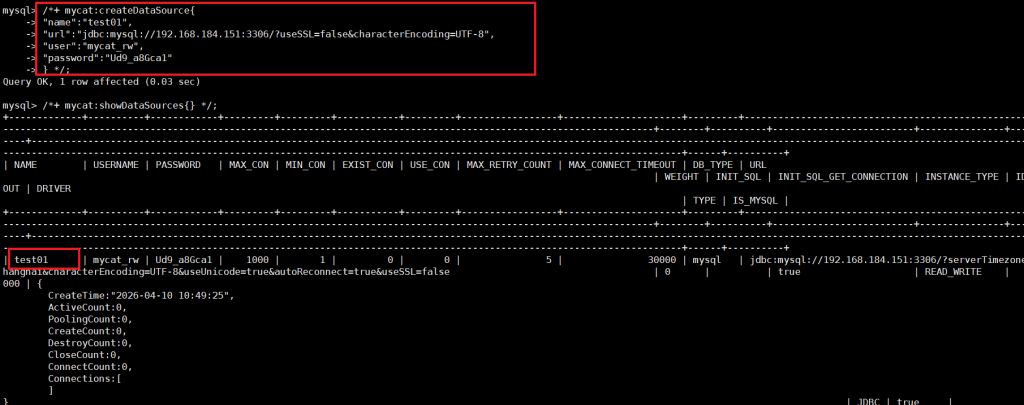
⚠️ 避坑提醒:数据源 URL 中无需指定具体数据库,后续逻辑库会映射到分片;MySQL 账号需授权 MyCAT 服务器 IP 访问(grant all on *.* to 'mycat_rw'@'192.168.184.153' identified by '密码';)。
3. 集群管理:主从架构配置
MyCAT 支持将多个数据源组成集群,实现读写分离或高可用。这里以「一主一从」架构为例:
-- 先创建主从数据源(示例中主从复用一个节点,实际需分开)
/*+ mycat:createDataSource{
"name":"test01",
"url":"jdbc:mysql://192.168.184.151:3306/?useSSL=false&characterEncoding=UTF-8",
"user":"mycat_rw",
"password":"Ud9_a8Gca1"
} */;
-- 创建集群(masters指定主库,replicas指定从库)
/*! mycat:createCluster{"name":"c_test_1","masters":["test01"],"replicas":["test01"]} */;
-- 查看集群配置
/*+ mycat:showClusters{} */;
-- 删除集群
/*! mycat:dropCluster{"name":"c_test_1"} */;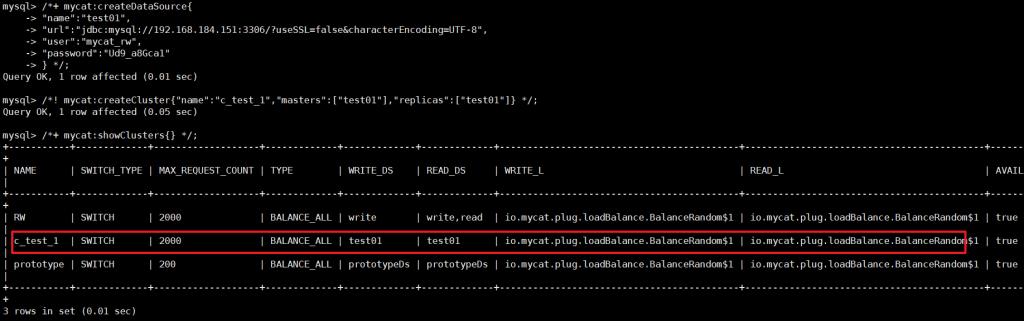
实际生产中,建议主从数据源使用不同 MySQL 节点,避免单点故障。
二、分库分表环境准备
本次实战规划:2 个集群(c0、c1),每个集群 1 主 1 从,逻辑库 sharding_maria 下包含 3 种表类型(全局表、分片表、ER 表)。
1. 配置数据源与集群
先创建 4 个数据源(2 主 2 从),再组成 2 个集群:
-- 创建主从数据源(c0集群:151主、152从;c1集群:153主从)
/*+ mycat:createDataSource{
"name":"maria_w0", -- c0主库
"url":"jdbc:mysql://192.168.184.151:3306/?useSSL=false&characterEncoding=UTF-8",
"user":"mycat_rw",
"password":"Ud9_a8Gca1"
} */;
/*+ mycat:createDataSource{
"name":"maria_r0", -- c0从库
"url":"jdbc:mysql://192.168.184.152:3306/?useSSL=false&characterEncoding=UTF-8",
"user":"mycat_rw",
"password":"Ud9_a8Gca1"
} */;
/*+ mycat:createDataSource{
"name":"maria_w1", -- c1主库
"url":"jdbc:mysql://192.168.184.153:3306/?useSSL=false&characterEncoding=UTF-8",
"user":"mycat_rw",
"password":"Ud9_a8Gca1"
} */;
/*+ mycat:createDataSource{
"name":"maria_r1", -- c1从库
"url":"jdbc:mysql://192.168.184.153:3306/?useSSL=false&characterEncoding=UTF-8",
"user":"mycat_rw",
"password":"Ud9_a8Gca1"
} */;
-- 创建集群
/*! mycat:createCluster{"name":"c0","masters":["maria_w0"],"replicas":["maria_r0"]} */;
/*! mycat:createCluster{"name":"c1","masters":["maria_w1"],"replicas":["maria_r1"]} */;
-- 验证:查看集群和数据源状态
/*+ mycat:showClusters{} */;
/*+ mycat:showDataSources{} */;
-- 删除集群
/*! mycat:dropCluster{"name":"maria_c0","masters":["maria_w0"],"replicas":["maria_r0"]} */;
/*! mycat:dropCluster{"name":"maria_c1","masters":["maria_w1"],"replicas":["maria_r1"]} */;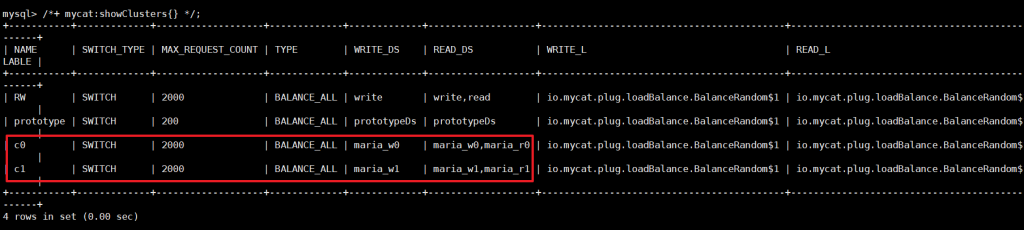
2. 创建逻辑库
逻辑库是 MyCAT 对外提供的「虚拟数据库」,应用程序连接时只需指定逻辑库名,无需关心底层分片:
create database sharding_maria; -- 与普通MySQL创建数据库语法一致
三、三种核心表类型配置(实战重点)
MyCAT 支持多种分片策略,不同表类型对应不同业务场景,下面逐一实操:
1. 全局表:全量数据同步(适合字典表)
全局表的特点是「所有分片都存储全量数据」,常用于频繁 Join 的字典表(如省份、性别字典),避免跨库 Join。
配置步骤:
-- 创建全局表(关键:指定broadcast分片规则)
create table sharding_maria.global_t1(
id int not null primary key,
name varchar(20), -- 字典名称
age int -- 扩展字段
)Engine=InnoDB broadcast; -- broadcast表示全局表
验证效果:
- 插入测试数据:
use sharding_maria;
insert into global_t1 values (1,'a',20),(2,'b',25),(3,'c',30);
- 分别登录底层 MySQL 节点(151、152、153)查询:
use sharding_maria;
select * from global_t1; -- 所有节点均能查询到全量数据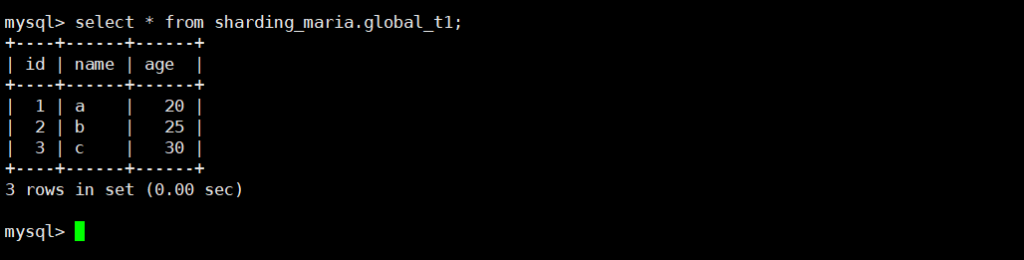
原理:
全局表的配置会自动同步到所有分片,插入 / 更新操作会广播到所有节点,保证数据一致性。
2. 分片表:数据拆分存储(适合大数据量表)
分片表会按指定规则将数据拆分到不同分片,减轻单库压力。这里以「哈希分片」为例(按 id 取模拆分)。
配置步骤:
-- 创建分片表(分库+分表:1个库分2张表)
CREATE TABLE `sharding_maria.hash_t1` (
`id` bigint NOT NULL AUTO_INCREMENT primary key,
name varchar(20),
age int
) ENGINE=InnoDB
DBPARTITION BY MOD_HASH(id) DBPARTITIONS 1 -- 分库规则:按id取模,1个库
TBPARTITION BY MOD_HASH(id) TBPARTITIONS 2; -- 分表规则:按id取模,2张表
DBPARTITIONS:分库数量(这里 1 个库,仅分表)TBPARTITIONS:分表数量(每个库下分 2 张表)- 分片字段:id(必须是查询高频字段,否则会全表扫描)
验证效果:
- 插入测试数据:
insert into hash_t1(name,age) values ('a',20),('b',25),('c',30),('d',35);
- 在 MyCAT 查询全量数据(自动聚合所有分片):
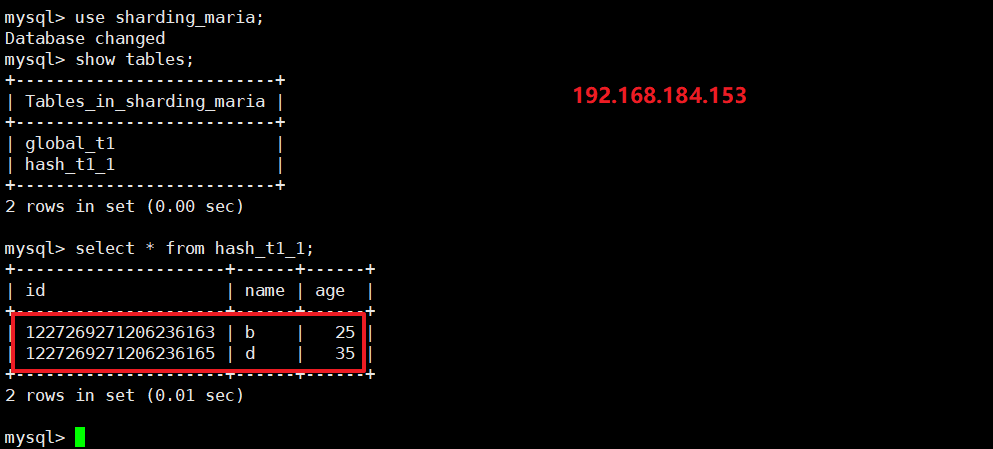
select * from hash_t1; -- 能看到4条数据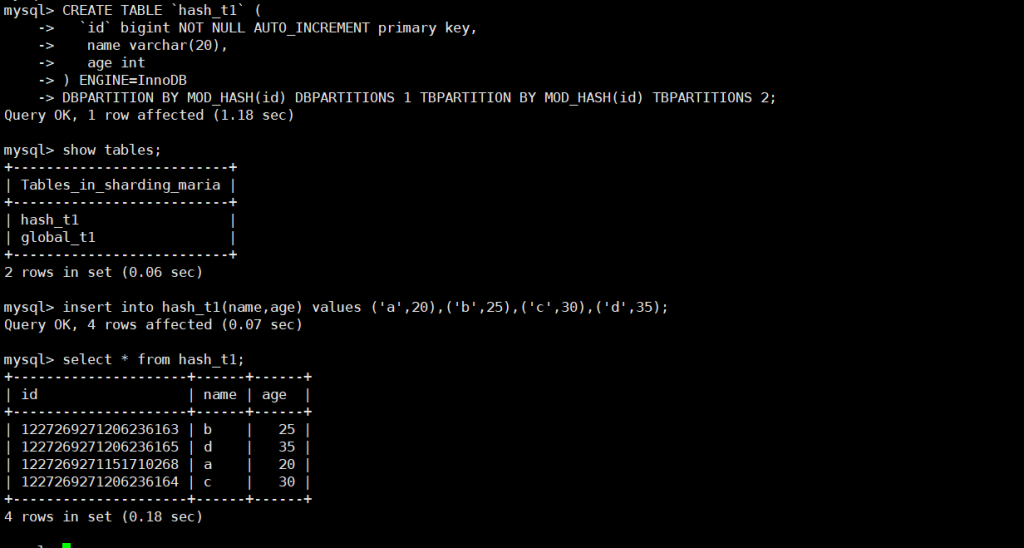
- 登录底层 MySQL 节点查询分片数据:
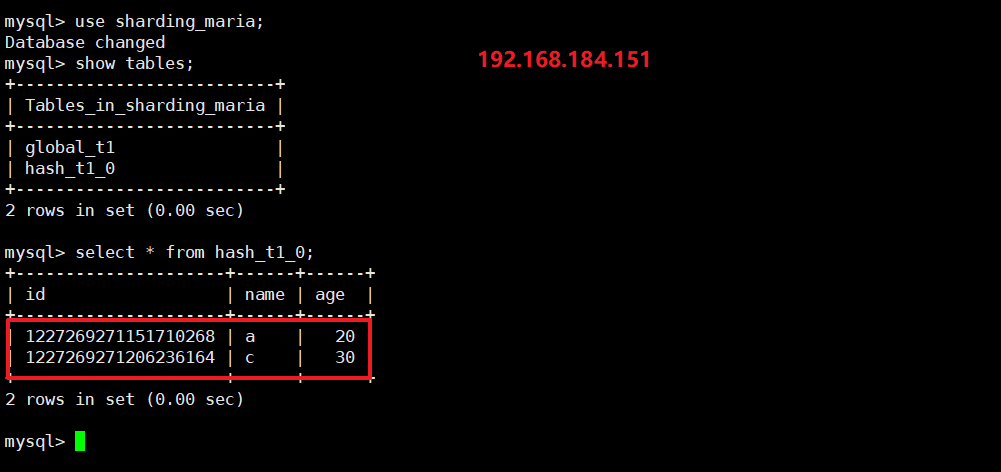
- 192.168.184.151:
select * from hash_t1_0;(存储 id 取模 0 的数据)
- 192.168.184.153:
select * from hash_t1_1;(存储 id 取模 1 的数据)
3. ER 表:关联表分片(避免跨库 Join)
ER 表是指「存在关联关系的表」(如学生表和成绩表),通过相同的分片规则(如按 user_id 分片),让关联数据存储在同一个分片,避免跨库 Join。
配置步骤:
-- 创建学生表(按user_id哈希分片)
CREATE TABLE `sharding_maria.student_info` (
`id` bigint NOT NULL AUTO_INCREMENT primary key,
`user_id` int, -- 分片字段
name varchar(10)
) ENGINE=InnoDB
dbpartition by mod_hash(user_id) dbpartitions 1
tbpartition by mod_hash(user_id) tbpartitions 4 ;
-- 创建成绩表(与学生表用相同的分片规则)
CREATE TABLE `sharding_maria.student_score` (
`id` bigint NOT NULL AUTO_INCREMENT primary key,
`user_id` int, -- 相同分片字段
`score` int DEFAULT NULL
) ENGINE=InnoDB
dbpartition by mod_hash(user_id) dbpartitions 1
tbpartition by mod_hash(user_id) tbpartitions 4 ;
验证效果:
- 查看 ER 关系(groupId 相同即为同一 ER 组):
/*+ mycat:showErGroup{}*/;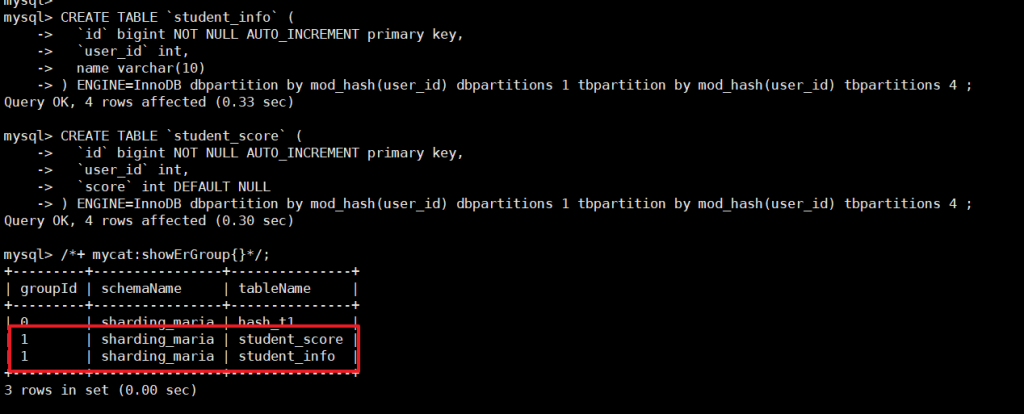
- 插入测试数据:
insert into student_info(user_id,name) values (1,'a'),(2,'b'),(3,'c');
insert into student_score(user_id,score) values (1,90),(2,80),(3,88);
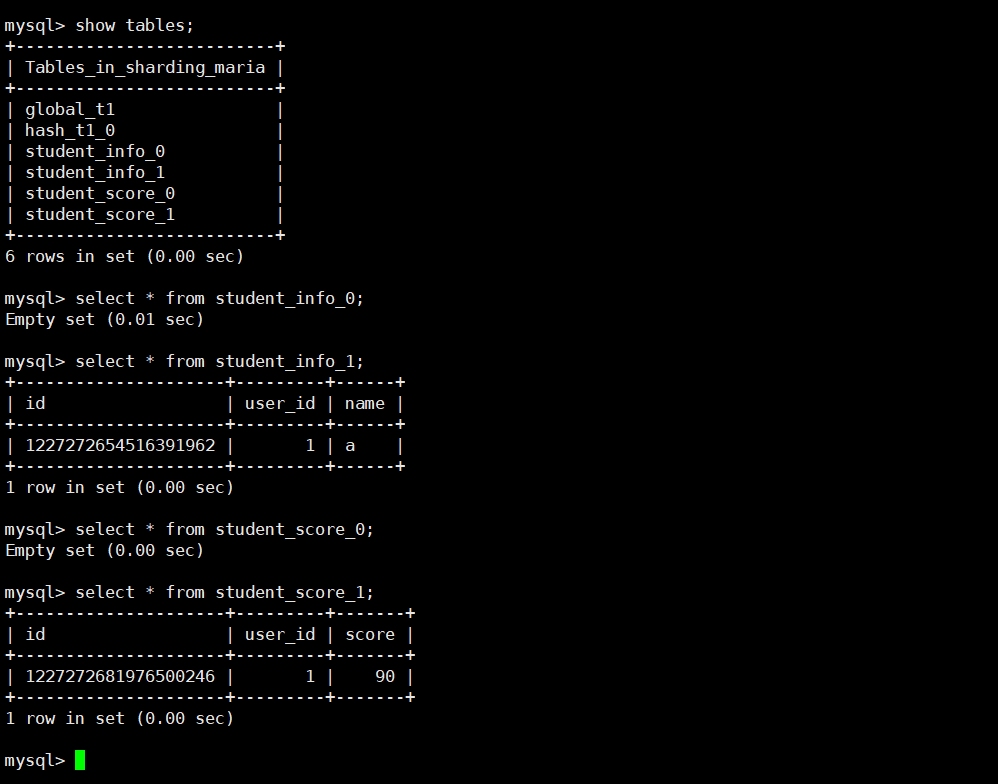
- 分片查询(关联数据在同一分片):
- 登录 192.168.184.151,查询
student_info_1 和student_score_1,会发现 user_id=1 的数据在同一分片中
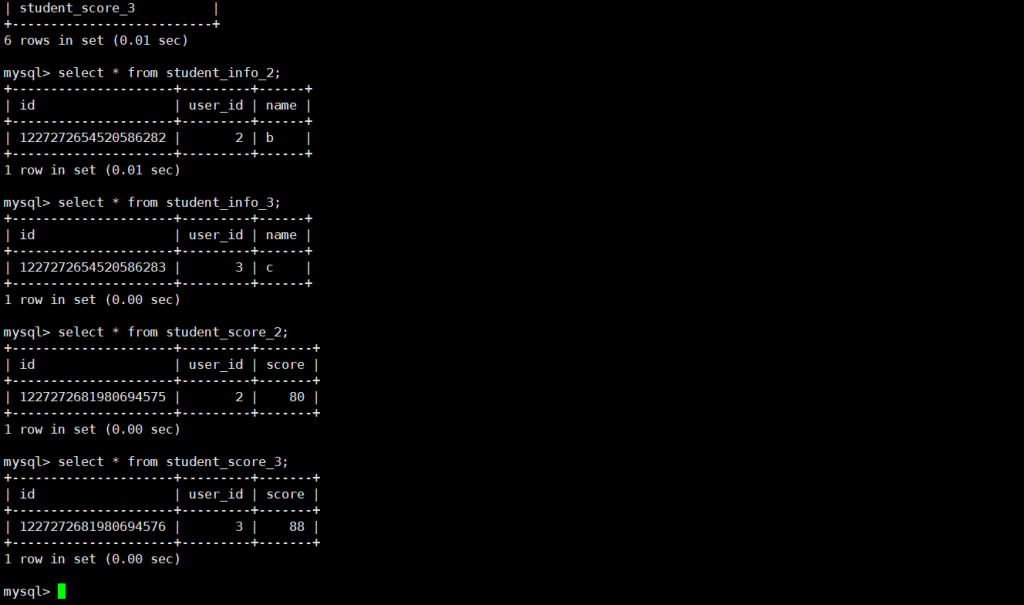
- 登录192.168.184.153,查询
student_info_2、student_info_3和student_score_2、student_score_3,会发现 user_id=2、user_id=3 的数据在同一分片中
- 执行 Join 查询(MyCAT 自动在同一分片执行,效率极高):
select a.user_id,a.name,b.score
from student_info a
left join student_score b on a.user_id=b.user_id;
四、总结与避坑指南
核心收获:
- MyCAT 通过「逻辑库 – 集群 – 数据源」三层架构,实现了分库分表的透明化(应用无需修改代码)
- 全局表适合字典表,分片表适合大数据量表,ER 表适合关联查询表
- 分片规则选择至关重要:哈希分片适合均匀分布,范围分片适合按时间 / 区间查询
避坑技巧:
- 数据源 URL 不要指定具体数据库,否则逻辑库无法映射
- 分片字段需是查询高频字段,避免「全分片扫描」
- 全局表数据量不宜过大,否则同步成本高
- ER 表必须使用相同的分片字段和规则,否则会跨库 Join
如果大家在实操中遇到问题,欢迎在评论区留言~

