

【MySQL】 核心复制技术全解析:从日志格式到 GTID 实践
大家好,我是云扬。
在 MySQL 数据库运维中,复制技术是实现数据备份、读写分离、高可用架构的核心基础。从早期的异步复制到现代的组复制、GTID 复制,MySQL 复制机制一直在迭代优化,平衡数据一致性、性能与可靠性。
今天这篇文章,我就带大家系统梳理 MySQL 中 7 类关键复制技术,结合日志格式原理、实操命令与落地场景,帮大家一次性吃透 MySQL 复制。
一、三种 Binlog 日志格式对复制的影响
Binlog 二进制日志是 MySQL 复制的核心载体,日志格式直接决定主从数据一致性和复制效率,MySQL 历史上有 3 种核心格式:
1.1 statement 格式:早期默认,一致性有风险
- 支持版本:MySQL 3.23 ~ 5.1.5(仅支持此格式)
- 核心特点:记录 SQL 语句本身(如
insert into...),而非数据行的变更;日志量小,性能开销低。 - 关键问题:涉及非确定性操作(如
uuid()、now())或跨库更新时,主从执行结果可能不一致 —— 因为 SQL 语句在主从库执行时的上下文不同。
实操验证:主从数据不一致场景
- 设置日志格式:主从库均切换为 statement 格式(需先停止复制)
stop slave; -- 停止从库复制
set global binlog_format=statement; -- 全局生效日志格式
start slave; -- 重启复制- 主库创建测试数据:使用
uuid()生成随机值
use maria; -- 切换到测试库
-- 创建测试表
create table statement_t1(
id int not null auto_increment primary key,
a varchar(100) -- 存储uuid值
);
-- 插入含非确定性函数的数据
insert into statement_t1(a) values (uuid());- 对比主从数据:执行
select * from statement_t1;后发现,主从库中a字段的 uuid 值完全不同 —— 这就是 statement 格式的一致性风险。
恢复操作:实验后切回安全格式
为避免后续问题,需将日志格式改回row(下文会讲):
stop slave;
set global binlog_format=row;
start slave;1.2 row 格式:一致性拉满,日志量偏大
- 支持版本:MySQL 5.1.5 及以上
- 核心特点:记录每一行数据的变更细节(如 “将 id=1 的行的 a 字段从 ‘xxx’ 改为 ‘yyy’”),而非 SQL 语句;完全规避非确定性操作的一致性问题。
- 缺点:日志量远大于 statement 格式(尤其是批量更新时),会增加磁盘 IO 与网络传输开销。
实操验证:主从数据一致
- 切换日志格式:主从库均设置为 row 格式
stop slave;
set global binlog_format=row;
start slave;- 主库插入数据:再次使用
uuid()
insert into statement_t1(a) values (uuid());- 对比主从数据:执行查询后,主从库的
a字段值完全一致 ——row 格式通过记录数据行变更,保证了复制一致性。
1.3 mixed 格式:折中方案,自动适配场景
- 支持版本:MySQL 5.1.8 及以上
- 核心特点:结合 statement 与 row 的优势,动态选择日志格式:
- 当 SQL 语句无一致性风险(如简单
update、delete)时,用 statement 格式(节省日志量); - 当 SQL 语句含非确定性操作(如
uuid()、limit+order by)时,自动切换为 row 格式(保证一致性)。 - 适用场景:既想减少日志量,又需避免一致性问题的场景(如普通业务系统的读写分离)。
二、异步复制:基础方案,存在数据丢失风险
异步复制是 MySQL 最早的复制模式,也是默认复制方式,其核心特点是 “主库不等待从库”。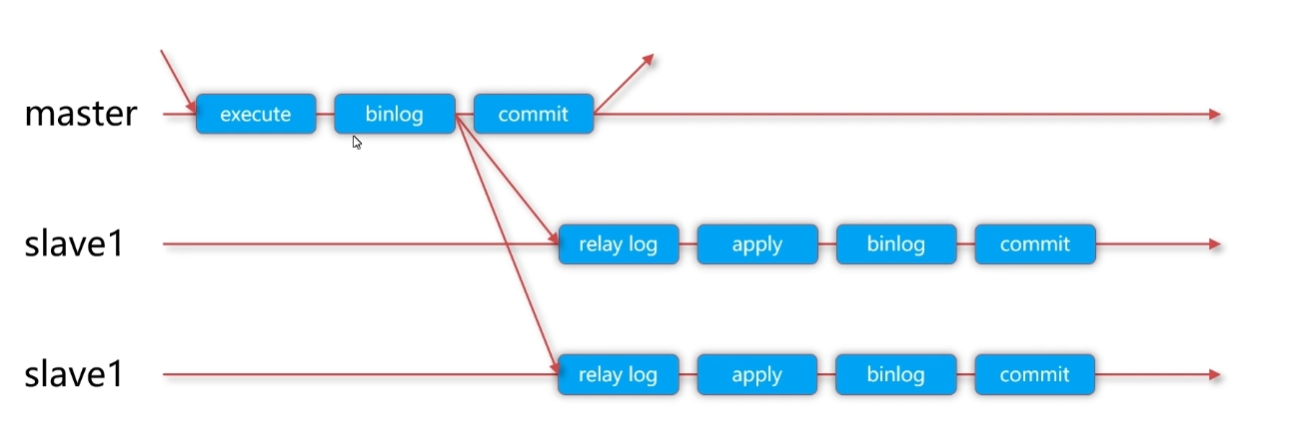
2.1 原理架构
- 主库侧:事务提交后,立即写入 Binlog,通过IO 线程将 Binlog 发送到从库的中继日志(Relay Log),无需等待从库确认,直接向客户端返回 “commit 成功”。
- 从库侧:通过SQL 线程读取中继日志,将 Binlog 解析为 SQL 语句并执行,最终同步数据。
(架构示意:主库 → [IO 线程] → 从库中继日志 → [SQL 线程] → 从库数据)
2.2 核心问题:数据丢失风险
若主库突然宕机(如断电、硬件故障),可能存在 “主库已提交但未同步到从库” 的事务 —— 此时从库提升为主库后,这部分数据会永久丢失,无法满足高可用场景的一致性要求。
为解决此问题,MySQL 5.5 引入了半同步复制。
三、半同步复制:确保日志至少同步到一个从库
半同步复制在异步复制基础上增加了 “主库等待从库确认” 的逻辑,核心目标是减少数据丢失风险。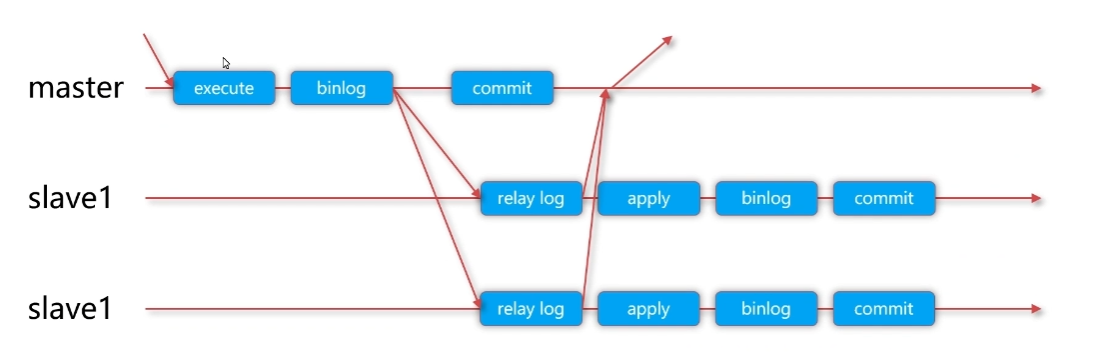
3.1 原理改进
- 主库提交事务后,写入 Binlog,通过 IO 线程发送到从库;
- 主库等待从库确认 “已接收 Binlog 并写入中继日志”(至少一个从库确认);
- 主库收到确认后,才向客户端返回 “commit 成功”;
- 从库仍通过 SQL 线程解析中继日志并执行。
相比异步复制,半同步复制保证了 “至少有一个从库持有最新 Binlog”,即便主库宕机,从库也能基于已接收的 Binlog 恢复数据,减少丢失概率。
3.2 实操配置:主从库分步部署
3.2.1 主库配置
- 安装半同步主库插件:
install plugin rpl_semi_sync_master soname 'semisync_master.so';- 验证插件安装:查看
mysql.plugin表,确认插件存在:
select * from mysql.plugin; -- 应显示rpl_semi_sync_master- 开启半同步复制:
set global rpl_semi_sync_master_enabled=1; -- 临时生效- 配置文件持久化(避免重启失效):
vim /data/mysql/conf/my.cnf
# 添加以下内容
plugin_load="rpl_semi_sync_master=semisync_master.so;rpl_semi_sync_slave=semisync_slave.so"
rpl_semi_sync_master_enabled = 1
rpl_semi_sync_slave_enabled = 1 # 主库也可作为从库,提前配置
# 重启MySQL生效
/etc/init.d/mysql.server restart3.2.2 从库配置
- 安装半同步从库插件:
install plugin rpl_semi_sync_slave soname 'semisync_slave.so';- 开启半同步复制:
set global rpl_semi_sync_slave_enabled=1; -- 临时生效- 配置文件持久化(同主库,需包含插件加载与启用参数),并重启 MySQL。
3.2.3 查看半同步状态
主从库均执行以下命令,确认Rpl_semi_sync_master_status或Rpl_semi_sync_slave_status为ON:
show global status like '%semi%';四、增强半同步复制:进一步降低数据丢失
MySQL 5.7 在半同步复制基础上,推出增强半同步复制,通过调整 “主库等待时机”,进一步降低数据丢失风险。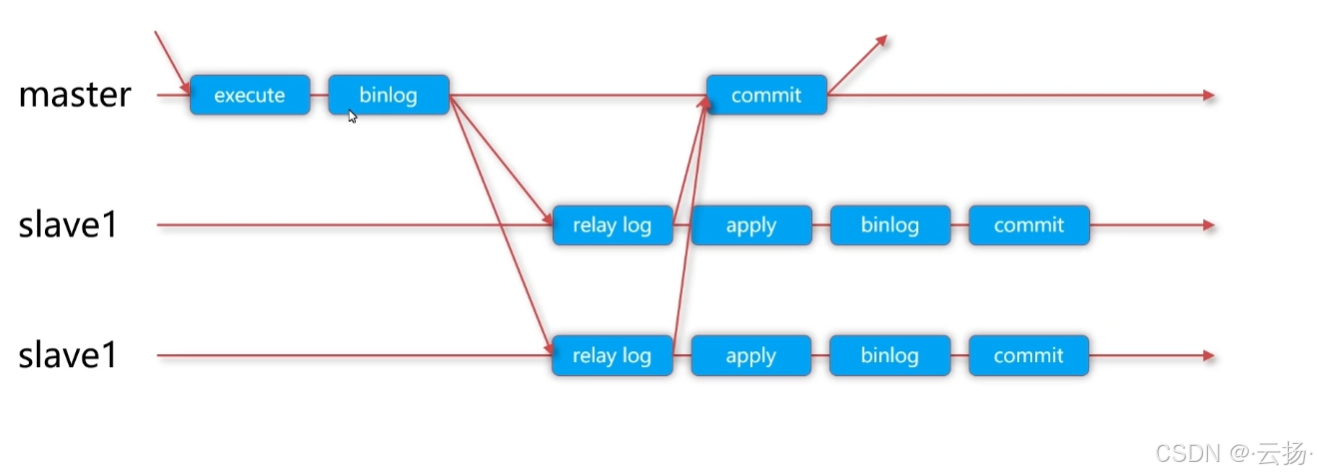
4.1 核心改进:调整等待点
半同步复制与增强半同步复制的核心区别在于主库的等待时机(由参数rpl_semi_sync_master_wait_point控制):
- 普通半同步(AFTER_COMMIT):主库先执行事务提交(修改存储引擎数据),再等待从库确认 Binlog;若主库等待超时,退化为异步复制 —— 此时主库已修改数据,但从库可能未收到 Binlog,仍有少量数据丢失风险。
- 增强半同步(AFTER_SYNC):主库先写入 Binlog,再等待从库确认 “Binlog 已写入中继日志并刷盘”,确认后才执行事务提交;若等待超时,主库不提交事务 —— 此时主库未修改数据,从库若已收到 Binlog,数据完全一致,无丢失风险。
注:参数默认值为 AFTER_SYNC(MySQL 5.7+),即默认启用增强半同步复制。
4.2 查看与切换等待点
- 查看当前等待点:
show global variables like 'rpl_semi_sync_master_wait_point';- 切换等待点(如需回退到普通半同步):
set global rpl_semi_sync_master_wait_point='AFTER_COMMIT';五、组复制:分布式集群的一致性保障
MySQL 5.7 推出组复制(Group Replication),适用于分布式集群场景,通过 “原子广播” 与 “冲突监测”,保证集群中多数节点的数据一致性。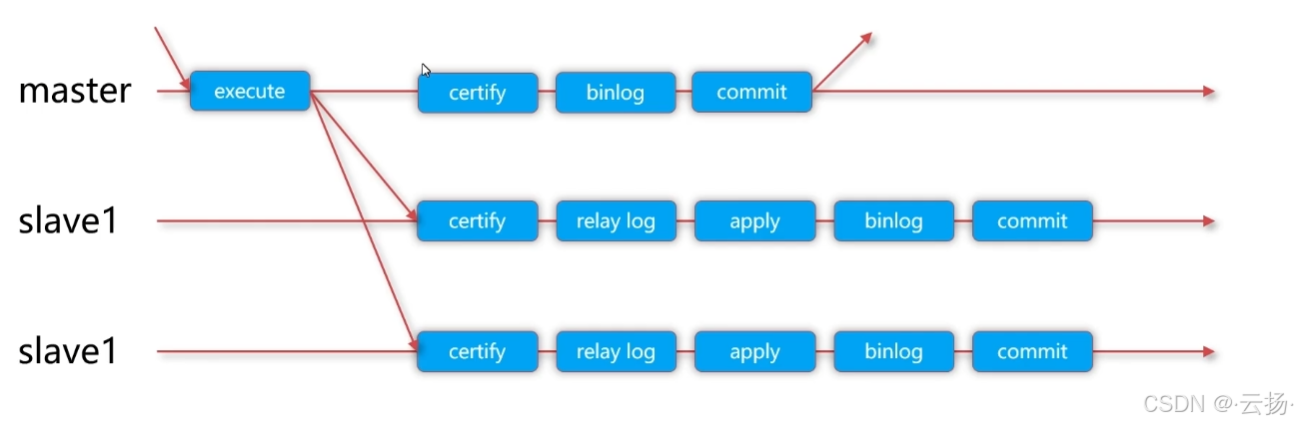
5.1 核心原理
- 原子广播:主库(或发起节点)的事务变更,通过 “原子广播协议” 发送给集群中所有节点,确保 “要么所有节点收到,要么都不收到”。
- 冲突监测:每个节点收到事务后,按相同规则排序,并检查事务是否与本地已执行事务冲突:
- 主库侧:冲突监测通过后,写入本地 Binlog,执行事务提交;若冲突,事务回滚。
- 从库侧:冲突监测通过后,将 Binlog 写入中继日志,通过 SQL 线程重放并提交;若冲突,丢弃该事务(避免数据不一致)。
- 多数派确认:事务需得到集群中多数节点(超过一半)的确认,才会最终提交 —— 确保集群分区时,仍能维持数据一致性。
5.2 适用场景
- 分布式数据库集群(如多主架构);
- 对数据一致性要求高的高可用场景(如金融、电商核心业务)。
六、并行复制:提升从库同步效率
传统复制中,从库仅用单个 SQL 线程重放中继日志,当主库写入压力大时,从库易出现 “复制延迟”。MySQL 通过并行复制,让从库用多个线程同时重放日志,降低延迟。
6.1 各版本并行复制演进
- MySQL 5.6:仅支持库级别并行—— 不同数据库的事务,可由不同 SQL 线程重放;同一数据库的事务仍串行执行(局限性大)。
- MySQL 5.7:支持表级别并行(基于
WRITE_SET)—— 通过分析事务修改的表,不同表的事务可并行重放;部分场景下支持行级别并行。 - MySQL 5.7.22+:支持基于 WRITE_SET 的行级别并行—— 通过分析事务修改的数据行(WRITE_SET 是行的哈希值),无行冲突的事务可并行重放,效率大幅提升。
七、基于 GTID 的复制:简化故障转移
MySQL 5.6 引入GTID(全局事务 ID),用 “全局唯一的事务 ID” 替代传统的 “Binlog 文件 + 位点”,简化复制架构的故障转移与维护。
7.1 GTID 的核心优势
传统 “基于位点的复制” 存在明显痛点:主库切换时,需手动查找新主库的 Binlog 文件与位点,操作复杂且易出错。GTID 通过以下特性解决此问题:
- 全局唯一:每个事务在集群中对应一个唯一的 GTID(格式:
uuid:事务序号),如65c07f5e-1e37-11ed-b657-fa163e0d61f4:101。 - 自动定位:从库只需知道主库的 GTID 集合,即可自动找到需同步的事务,无需手动指定位点。
- 一致性校验:通过对比主从库的 GTID 集合,可快速判断数据是否一致(若集合相同,数据一致)。
7.2 GTID 复制的核心价值
- 简化故障转移:主库宕机后,从库切换为主库时,新从库可直接基于 GTID 同步,无需人工干预。
- 易于维护:无需记录与传递 Binlog 文件和位点,降低运维成本。
总结:复制技术选型建议
最后给大家整理了生产环境选型表,直接对照场景选用即可:
| 场景需求 | 推荐技术 |
| 简单读写分离,容忍少量延迟 | 异步复制 + mixed 日志格式 |
| 降低数据丢失风险 | 增强半同步复制(AFTER_SYNC) |
| 分布式集群,需强一致性 | 组复制 |
| 主库写入压力大,避免从库延迟 | 并行复制(MySQL 5.7.22+) |
| 频繁主从切换,简化运维 | 基于 GTID 的复制 |
以上就是 MySQL 核心复制技术的全解析,从日志基础到高可用集群方案,覆盖日常运维 90% 场景。后续我会继续分享 MySQL 主从故障排查、延迟优化等实战内容,欢迎关注交流。

