

【MySQL】MySQL 复制核心参数详解
大家好,我是云扬~ 今天整理了 MySQL 复制中最常用的核心参数,结合实际运维场景拆解配置逻辑,不管是搭建基础主从架构,还是双主互备模式,这些参数都是保障数据一致性的关键。
一、复制日志基础配置
复制的核心依赖二进制日志,这两个参数是开启复制的前提:
log_bin:必须启用!记录所有数据变更操作(增删改),是主从同步的数据源。建议指定日志存储路径,比如log_bin=/data/mysql/binlog/mysql-bin,方便管理和备份。binlog_format:日志格式直接影响复制可靠性,推荐生产环境用ROW模式(行级复制),避免 Statement 模式的语法兼容性问题,虽然日志量稍大,但数据一致性更有保障。log_slave_updates:从库是否记录复制过来的变更。如果需要搭建级联复制(从库再作为其他从库的主库),必须设为ON,否则二级从库无法获取数据。
二、GTID 复制关键参数(推荐生产使用)
GTID 模式能简化主从切换,避免传统复制的日志文件 + 偏移量定位问题,核心参数如下:
gtid_mode:控制 GTID 启用状态,生产环境直接设为ON(强制模式),新搭建的集群建议默认开启。如果是旧集群迁移,可先通过OFF_PERMISSIVE、ON_PERMISSIVE过渡,再切换到ON。OFF:不启用 GTID,事务无 GTID 标识。OFF_PERMISSIVE:新事务不使用 GTID,但允许处理带 GTID 的事务(用于过渡)。ON_PERMISSIVE:新事务使用 GTID,同时兼容无 GTID 的旧事务。ON:强制启用 GTID,所有事务都被分配 GTID,适用于主从复制环境。
enforce_gtid_consistency=ON:严格模式下会禁止三类危险操作 —— 创建临时表的事务、混合事务 / 非事务表、CREATE TABLE ... SELECT,这些操作会导致 GTID 追踪混乱,务必规避。
实战小贴士:开启 GTID 后,主从切换时无需手动找日志文件和偏移量,直接用
MASTER_AUTO_POSITION=1即可自动同步,效率大幅提升。
三、主从架构核心差异配置
主从复制的核心是区分实例角色,这两个参数是基础:
server_id:实例唯一标识,主从必须不同!建议按机房 + 服务器编号规划(比如主库 101,从库 102),避免后续扩容冲突。从库通过识别主库的server_id防止数据回传,避免循环同步。read_only:控制数据库是否允许写入操作。通常主库设置为read_only=0(默认,可读写),负责处理业务的写请求;从库设置为read_only=1(只读),避免从库被意外写入数据,保证主从数据一致性,但要注意 —— 这个参数对 root 等超级用户无效!生产环境需额外创建业务只读用户,或通过权限控制禁止超级用户在从库写操作,防止误改数据。
四、双主互备配置实战
双主架构(主主复制)需解决自增主键冲突,关键靠两个自增参数:
auto_increment_increment:定义自增列每次增长的步长。在双主架构中,通常设置为 “2”,确保两个主库生成的自增值不会重叠(例如一个库生成奇数,另一个生成偶数)。auto_increment_offset:定义自增列的起始偏移量。两个主库需设置不同的偏移值(如一个设为 “1”,另一个设为 “2”),配合步长为 2 时,可分别生成 “1,3,5…” 和 “2,4,6…” 的自增值,彻底避免主键冲突。
双主配置步骤(实操版)
假设两个实例信息:
- 主库 A:IP=192.168.184.151,server_id=184151;
- 主库 B:IP=192.168.184.152,server_id=184152。
步骤 1:基础参数配置(两库均需配置)
编辑my.cnf,添加以下持久化配置:
# 基础日志配置
log_bin = mysql-bin
binlog_format = MIXED
log_slave_updates = ON # 双主需互相同步,必须开启
# GTID配置(推荐启用)
gtid_mode = ON
enforce_gtid_consistency = ON
server_id = 184151 # 主库A设184151,主库B设184152
# 自增参数(避免主键冲突)
auto_increment_increment = 2
auto_increment_offset = 1 # 主库A设1,主库B设2
# 从库只读(双主均需,避免意外写)
read_only = 1
super_read_only = 1 # MySQL 5.7+ 可选,限制root写配置后重启 MySQL 生效:systemctl restart mysqld。
步骤 2:创建复制账号(两库均需执行)
在主库 A 和主库 B 分别创建用于复制的账号(如repl),授予REPLICATION SLAVE权限:
CREATE USER 'repl'@'%' IDENTIFIED BY 'Uid_dQc63'; # 密码根据实际需求修改
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
FLUSH PRIVILEGES;步骤 3:配置互为主从(关键步骤)
① 主库 A 配置为 “主库 B 的从库”
在主库 A 执行以下 SQL,指定主库 B 的信息:
STOP SLAVE; # 若之前有复制关系,先停止
CHANGE MASTER TO
MASTER_HOST='192.168.184.152', # 主库B的IP
MASTER_USER='repl',
MASTER_PASSWORD='Uid_dQc63',
MASTER_AUTO_POSITION=1; # 启用GTID自动定位(无需手动指定日志文件和偏移量)
START SLAVE; # 启动复制
SHOW SLAVE STATUS\G # 验证状态,确保Slave_IO_Running和Slave_SQL_Running均为Yes② 主库 B 配置为 “主库 A 的从库”
在主库 B 执行类似 SQL,指定主库 A 的 IP:
STOP SLAVE;
CHANGE MASTER TO
MASTER_HOST='192.168.184.151', # 主库A的IP
MASTER_USER='repl',
MASTER_PASSWORD='Uid_dQc63',
MASTER_AUTO_POSITION=1;
START SLAVE;
SHOW SLAVE STATUS\G # 同样验证两个线程为Yes步骤 4:解决常见报错(防火墙问题)
若执行SHOW SLAVE STATUS\G时出现 “连接超时” 或 “拒绝连接”,大概率是防火墙拦截了 3306 端口,在从库执行以下命令清空规则(生产环境建议精确配置端口,而非直接清空):
iptables -F # 临时关闭防火墙规则,重启后失效;生产环境需配置:iptables -A INPUT -p tcp --dport 3306 -j ACCEPT步骤 5:测试双主同步效果
① 主库 A 插入数据
USE maria; # 切换到测试库(需提前创建:CREATE DATABASE maria;)
# 创建测试表
CREATE TABLE auto_increment_t1(
id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
a VARCHAR(10)
);
# 插入2条数据
INSERT INTO auto_increment_t1(a) VALUES ('aaa'), ('bbb');
# 查询结果:id为1、3(符合offset=1,步长2)
SELECT * FROM auto_increment_t1;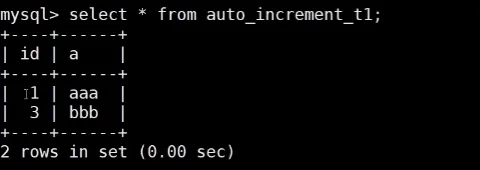
② 主库 B 插入数据
USE maria;
# 插入2条数据
INSERT INTO auto_increment_t1(a) VALUES ('ccc'), ('ddd');
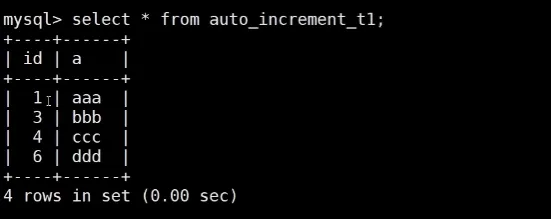
# 查询结果:id为1、3、4、6(符合offset=2,步长2)
SELECT * FROM auto_increment_t1;③ 验证同步一致性
在主库 A 查询主库 B 插入的数据,或在主库 B 查询主库 A 插入的数据,若能看到 4 条记录(id=1、3、4、6),则双主同步正常。
五、复制过滤参数(按需使用)
实际场景中可能需要同步部分库表,这些参数可以精准控制:
| 参数 | 作用 |
| replicate_do_db | 只同步某个库 |
| replicate_ignore_db | 忽略同步某个库 |
| replicate_do_table | 只同步某些表 |
| replicate_ignore_table | 忽略同步某些表 |
| replicate_wild_do_table | 指定同步某些表,支持正则 |
| replicate_wild_ignore_table | 忽略同步某一些表,支持正则 |
| binlog_do_db | 只记录指定数据库的Binlog |
| binlog_ignore_db | 不记录指定数据库的Binlog |
建议优先在从库配置过滤规则(replicate_* 系列),主库尽量保留完整日志,方便后续数据恢复。
六、性能优化相关配置
6.1 多线程复制
传统复制中,从库仅用 1 个线程重放日志,高并发场景下易出现 “复制延迟”。多线程复制通过多个 worker 线程并行重放,提升效率:
slave_parallel_workers=N:设置并行 worker 线程数(N 建议为 CPU 核心数的 1-2 倍,如 8 核 CPU 设为 8 或 16);slave_parallel_type=LOGICAL_CLOCK:基于事务逻辑时钟并行(MySQL 5.7 + 支持),仅对无依赖的事务并行重放,避免数据不一致。
配置建议:高并发主从架构必配,可显著降低复制延迟。
| 参数 | 作用 |
| slave_parallel_workers | 控制复制的线程数 |
| slave_parallel_type | 控制并行复制的策略 |
| binlog_transaction_dependency_tracking | 5.7.22新增的控制并发策略的参数 |
| binlog_group_commit_sync_delay | 控制将二进制日志文件同步到磁盘之前二进制日志提交等待的微秒数 |
6.2 半同步复制
异步复制中,主库发送日志后立即返回,若主库崩溃且日志未同步到从库,会导致数据丢失。半同步复制要求主库等待至少 1 个从库确认收到日志后再返回,提升安全性:
- 加载插件:主库
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';,从库INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';; - 启用半同步:主库
SET GLOBAL rpl_semi_sync_master_enabled=1;,从库SET GLOBAL rpl_semi_sync_slave_enabled=1;; - 超时配置:
SET GLOBAL rpl_semi_sync_master_timeout=1000;(1 秒超时后自动退化为异步复制,避免业务阻塞)。
适用场景:对数据一致性要求高的场景(如金融、电商核心业务),需权衡网络延迟对主库性能的影响。
| 参数 | 作用 |
| rpl_semi_sync_master_enabled | 主库开启半同步复制 |
| rpl_semi_sync_slave_enabled | 从库开启半同步复制 |
| rpl_semi_sync_master_wait_point | 是否开启增强半同步复制 |
总结
MySQL 复制的核心是 “参数配置 + 场景匹配”:基础主从重点关注 server_id 和 read_only;GTID 模式简化运维,推荐生产落地;双主架构核心解决自增冲突;过滤和并行参数则根据业务需求灵活调整。
实际配置时一定要先测试,尤其是双主和 GTID 模式,建议先在测试环境验证数据同步一致性,再推广到生产。如果大家有复制配置的坑或者优化经验,欢迎在评论区交流~

