

【MySQL】MySQL 误删库急救!用复制同步实现数据无损恢复
作为后端开发者,谁没经历过手滑误删库的绝望时刻?上周我在测试环境调试时,不小心执行了drop database,瞬间冷汗直流 —— 还好提前做了全备,最终通过「全备 + 主从复制回档」的方案成功恢复数据。今天就把这套实战流程整理出来,希望能帮大家避开踩坑!
一、核心思路
误删库后的数据恢复,本质是「回到误操作前的时间点」。核心逻辑如下:
- 用全备数据搭建临时从库(与原实例版本一致)
- 将从库接入原实例的复制链路,但只同步到误操作前的事务
- 从临时从库导出误删的库数据,导回原实例
这种方案的优势是不影响原实例运行,且能精准恢复到指定时间点,适合生产环境应急使用。
二、准备阶段(提前做好,关键!)
恢复的前提是「有全备」,所以日常一定要养成定时备份的习惯!以下是实操步骤:
1. 准备测试数据(模拟业务场景)
先创建测试库和表,写入基础数据:
create database recover;
use recover;
CREATE TABLE test_recover (
id int NOT NULL AUTO_INCREMENT,
a int NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB CHARSET=utf8mb4;
insert into test_recover values (1,1),(2,2);
2. 创建备份专用用户
用 xtrabackup 备份需要特定权限,创建专用用户更安全:
CREATE USER `u_xtrabackup`@`localhost` IDENTIFIED WITH MYSQL_NATIVE_PASSWORD BY 'Ijnbgt@123';
-- 授权必要权限,避免过度授权
GRANT SELECT, RELOAD, PROCESS, SUPER, LOCK TABLES,BACKUP_ADMIN ON *.* TO `u_xtrabackup`@`localhost`;
3. 执行全量备份
用 xtrabackup 做流式备份,方便传输到临时从库:
cd /data/backup
xtrabackup --defaults-file=/data/mysql/conf/my.cnf -uu_xtrabackup -p'Ijnbgt@123' --backup --stream=xbstream --target-dir=./ >/data/backup/xtrabackup.xbstream
👉 提示:备份后建议校验文件完整性,避免传输过程中损坏。
三、模拟误操作(还原真实场景)
1. 写入增量数据
全备后继续写入新数据,模拟业务持续运行:
use recover;
insert into test_recover values (3,3); -- 这行数据会在全备后产生
2. 模拟误删库
手滑时刻来临(实际操作中一定要三思!):
drop database recover;
此时原实例中的 recover 库已被删除,接下来进入紧急恢复流程。
四、核心恢复步骤(重点!)
1. 搭建临时从库并恢复全备
(1)准备临时实例
在另一台机器(IP:192.168.184.152)上安装与原实例相同版本的 MySQL,提前清空数据目录和 binlog 目录:
# 停止临时实例
/etc/init.d/mysql.server stop
# 清空数据和binlog(谨慎!仅临时实例执行)
rm /data/mysql/data/* -rf
rm /data/mysql/binlog/* -rf
(2)传输并解压全备文件
将原实例的全备文件传到临时实例:
scp /data/backup/xtrabackup.xbstream 192.168.184.152:/data/backup/recover
在临时实例解压并准备备份:
cd /data/backup/recover
# 解压xbstream文件
xbstream -x < xtrabackup.xbstream
# 准备备份(使数据可用)
xtrabackup --prepare --target-dir=./
# 复制备份到数据目录
xtrabackup --defaults-file=/data/mysql/conf/my.cnf --copy-back --target-dir=./
# 授权数据目录
chown -R mysql.mysql /data/mysql
(3)启动临时实例
/etc/init.d/mysql.server start
2. 配置主从复制(关键:不同步误操作)
(1)建立复制关系但不启动
在临时实例执行以下 SQL,连接原实例(主库),但切记不要启动复制:
stop slave;
reset slave;
change master to
master_host='192.168.184.151', -- 原实例IP
master_user='repl', -- 复制专用用户(需提前在主库创建)
master_password='Uid_dQc63',
master_auto_position = 1; -- 基于GTID复制(推荐)
👉 坑点提醒:如果此时启动 slave,会同步主库的所有操作(包括 drop database),导致恢复失败!
(2)找到误操作的 GTID
需要确定「删除库」这个事务的 GTID,才能精准停止同步:
# 到原实例的binlog目录,导出指定时间范围的binlog
cd /data/mysql/binlog
mysqlbinlog mysql-bin.000030 --start-datetime='2025-03-05 21:44:00' --stop-datetime='2023-03-05 21:47:00' --base64-output=decode-rows -v >/data/backup/1.sql
打开 1.sql 文件,查找DROP TABLE或DROP DATABASE语句对应的 GTID:
SET @@SESSION.GTID_NEXT= '4d197ac0-07e6-11f1-a60e-000c295cba4b:3106'/*!*/;
......
drop database recover/*!*/;
这里的4d197ac0-07e6-11f1-a60e-000c295cba4b:3106就是误操作的 GTID。
(3)同步到误操作前的事务
先启动 IO 线程拉取主库 binlog,再启动 SQL 线程到误操作前一个事务:
-- 启动IO线程(拉取binlog)
start slave io_thread;
-- 启动SQL线程,同步到误操作前
start slave sql_thread until sql_before_gtids='4d197ac0-07e6-11f1-a60e-000c295cba4b:3106';
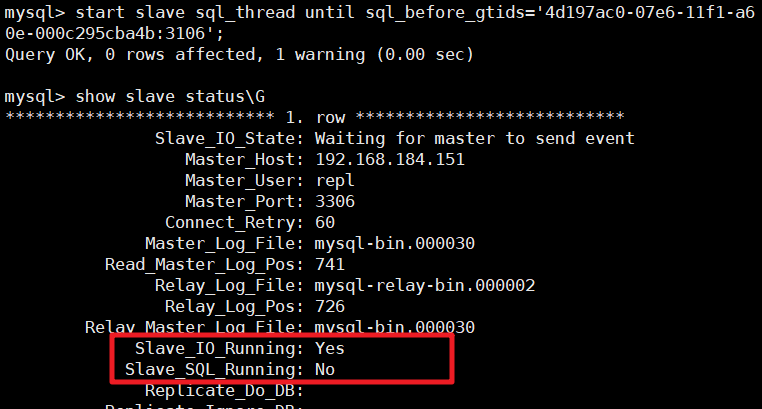
验证同步状态:
show slave status\G当看到Slave_IO_Running: Yes且Slave_SQL_Running: No时,说明已同步到误操作前,数据完好!
3. 导出并恢复数据
(1)从临时从库导出数据
mysqldump -u'root' -p --set-gtid-purged=off -B recover >recover.sql
👉 注意:--set-gtid-purged=off避免导入时产生 GTID 冲突。
(2)导回原实例
# 传输备份文件到原实例
scp recover.sql 192.168.184.151:/data/backup/
# 原实例导入数据
mysql -uroot -p < /data/backup/recover.sql
(3)验证恢复结果
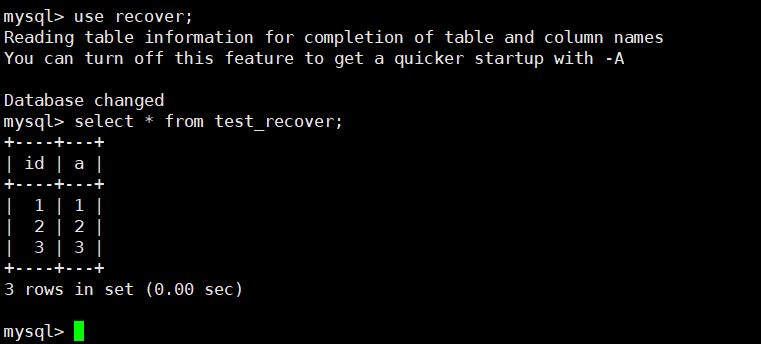
use recover;
select * from test_recover;
如果查询结果包含 3 行数据(1,1)、(2,2)、(3,3),说明恢复成功!
五、实战经验总结
- 日常备份是基础:建议用 xtrabackup 做全备 + binlog 增量备份,定期校验备份可用性。
- 提前准备临时实例:每个机房预留相同版本的 MySQL 实例,避免恢复时临时搭建耽误时间。
- 复制配置要谨慎:务必先停止 SQL 线程,找到准确的 GTID 再同步,避免同步误操作。
- 数据验证不可少:恢复后一定要结合业务场景验证数据完整性,避免遗漏。
误删库不可怕,关键是有应急预案和熟练的操作流程。希望这篇文章能帮大家在紧急时刻少走弯路,欢迎在评论区分享你的恢复经验或疑问!

