

【Java】String.intern() 深度解析:原理、案例与最佳实践
大家好,我是云扬~ 今天咱们深入聊聊 Java 中 String.intern () 方法的核心原理与实战场景。作为 Java 开发者,字符串处理是日常工作的高频场景,而 intern () 方法的正确使用能帮我们优化内存占用,但不少同学对它的底层逻辑和版本差异仍有困惑。这篇文章就结合具体代码实例,把 intern () 的来龙去脉讲透!
一、字符串对象的创建机制(基础铺垫)
在聊 intern () 之前,必须先明确 Java 中字符串对象的创建规则 —— 这是理解 intern () 的关键:
1. 双引号声明字符串
String s = "云扬三妹";
- 直接在字符串常量池中创建对象(若已存在则直接引用)
- s 的引用指向常量池中的对象
2. new 关键字创建字符串
String s = new String("云扬三妹");
- 执行逻辑:
- 先检查字符串常量池是否存在 “云扬三妹”,不存在则创建
- 无论常量池是否存在,都会在堆内存中创建新对象
- s 的引用指向堆中的对象(而非常量池)
3. 字符串拼接(重点注意)
String s1 = new String("云扬") + new String("三妹");
- 底层编译后等价于:
String s1 = new StringBuilder()
.append("云扬")
.append("三妹")
.toString();
- 最终创建的对象:
- 常量池:”云扬”、”三妹”(2 个对象)
- 堆内存:”云扬”、”三妹”(2 个匿名对象)+ “云扬三妹”(拼接结果对象)
- 关键结论:拼接结果 “云扬三妹” 仅存在于堆中,常量池中不会自动创建
二、String.intern () 核心作用
intern () 是 String 类的本地方法,核心功能是:将字符串对象的引用(或对象本身)存入字符串常量池,并返回常量池中的引用。
但它的执行逻辑在 Java 7 前后有重大变化 —— 根源是字符串常量池的存储位置迁移:
- Java 7 之前:常量池在永久代(独立于堆)
- Java 7 及之后:常量池迁移到堆内存(与普通对象同区域)
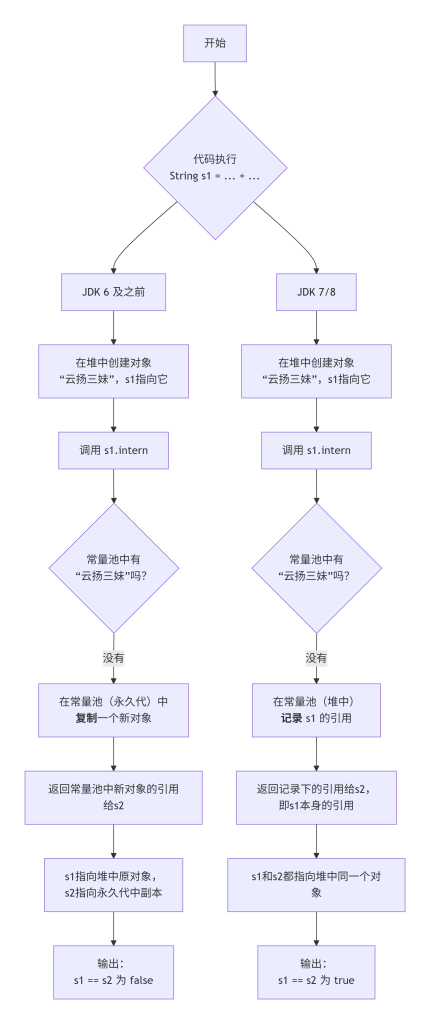
三、intern () 版本差异对比(附代码案例)
案例 1:Java 7+ 环境下的执行逻辑
// 案例1:常量池已存在目标字符串
String s1 = new String("云扬三妹"); // 堆中创建对象,常量池已存在"云扬三妹"
String s2 = s1.intern(); // 常量池存在,直接返回常量池引用
System.out.println(s1 == s2); // 输出:false
- 解释:
- s1 指向堆对象,s2 指向常量池对象,引用地址不同
// 案例2:常量池不存在目标字符串
String s1 = new String("云扬") + new String("三妹"); // 堆中有"云扬三妹",常量池无
String s2 = s1.intern(); // 常量池不存在,保存堆对象的引用
System.out.println(s1 == s2); // 输出:true
- 解释:
- Java 7+ 优化:常量池无需重复创建对象,直接存储堆中已有对象的引用
- s1 和 s2 最终指向同一个堆对象,引用地址相同
案例 3:Java 7 之前的执行逻辑(对比参考)
String s1 = new String("云扬") + new String("三妹");
String s2 = s1.intern();
System.out.println(s1 == s2); // 输出:false(与Java7+相反)
- 解释:
- 永久代与堆是独立区域,intern () 会在常量池重新创建 “云扬三妹” 对象
- s1 指向堆对象,s2 指向永久代常量池对象,地址不同
四、intern () 的实际应用场景
1. 内存优化:重复字符串去重
当系统中存在大量重复字符串(如用户昵称、商品名称)时,使用 intern () 可减少内存占用:
// 优化前:1000个重复字符串占用1000个堆对象内存
List<String> list = new ArrayList<>();
for(int i = 0; i<1000 ; i++) {
list.add(new String("Java程序员"));
}
// 优化后:仅占用1个堆对象内存(常量池存储引用)
// 优化前:1000个重复字符串占用1000个堆对象内存
List<String> list = new ArrayList<>();
for(int i = 0; i<1000 ; i++) {
list.add(new String("Java程序员").intern());
}
2. 字符串比较:避免 equals () 的性能开销
String a = "云扬".intern();
String b = "云扬".intern();
if (a == b) { // 直接比较引用,比equals()更快(无需遍历字符)
System.out.println("字符串相等");
}
五、使用 intern () 的注意事项(避坑指南)
- 不可滥用缓存:
- 字符串常量池本质是固定大小的
StringTable(默认大小:Java6=1009,Java7+=60013) - 若存入过多不重复字符串,会导致哈希冲突加剧,链表变长,查询性能下降
- 字符串常量池本质是固定大小的
- 区分场景使用:
- 适合场景:高频重复的短字符串(如枚举值、配置项)
- 不适合场景:低频、超长字符串(如文本内容)—— 缓存收益小于内存开销
- 版本兼容性:
- 若项目需兼容 Java 7 以下版本,需谨慎使用 intern (),避免内存泄漏(永久代空间有限)
六、总结
- String.intern () 的核心价值:复用字符串对象,减少内存占用
- Java 7+ 关键优化:常量池迁移至堆,intern () 直接存储堆对象引用,效率更高
- 最佳实践:仅对高频重复的短字符串使用 intern (),避免过度缓存
希望这篇文章能帮大家彻底搞懂 intern ()!如果有疑问或不同见解,欢迎在评论区交流~ 下期我们聊聊 String 的其他底层机制,敬请关注!

